Flink standalone session cluster 安装与配置
JDK 11 + Flink 1.17
Flink 程序结构
Flink 部署
Session mode
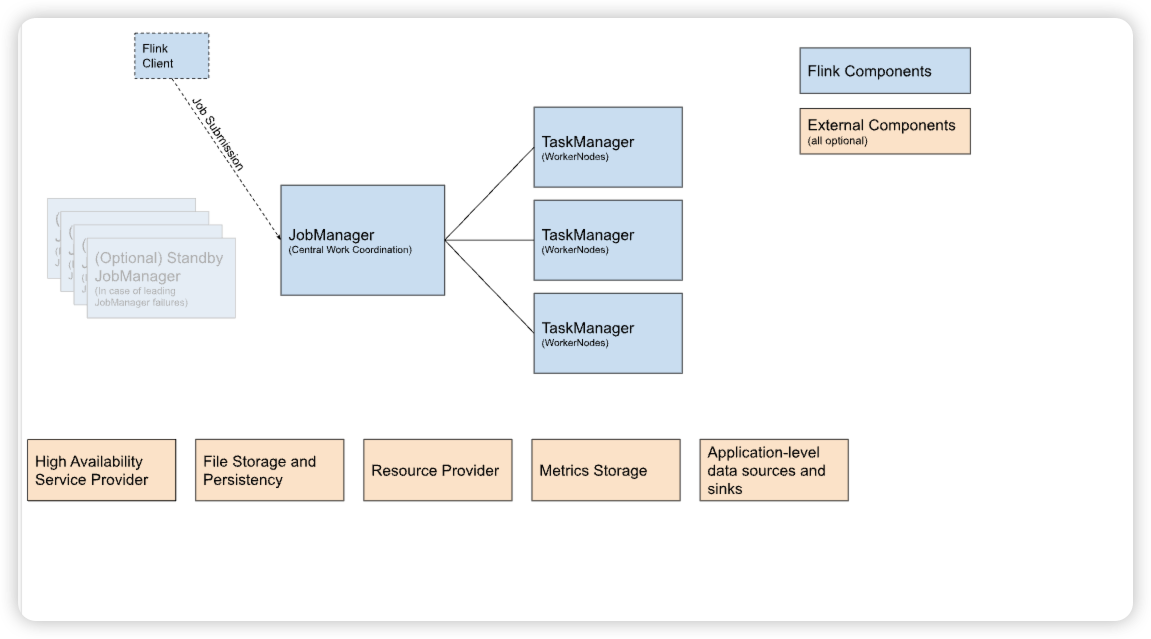
特征
运行特征: 集群生命周期:在 Flink Session 集群中,客户端连接到一个预先存在的、长期运行的集群,该集群可以接受多个作业提交。即使所有作业完成后,集群(和 JobManager)仍将继续运行直到手动停止 session 为止。因此,Flink Session 集群的寿命不受任何 Flink 作业寿命的约束。
资源隔离:TaskManager slot 由 ResourceManager 在提交作业时分配,并在作业完成时释放。由于所有作业都共享同一集群,因此在集群资源方面存在一些竞争 — 例如提交工作阶段的网络带宽。此共享设置的局限性在于,如果 TaskManager 崩溃,则在此 TaskManager 上运行 task 的所有作业都将失败;类似的,如果 JobManager 上发生一些致命错误,它将影响集群中正在运行的所有作业。
其他注意事项:拥有一个预先存在的集群可以节省大量时间申请资源和启动 TaskManager。有种场景很重要,作业执行时间短并且启动时间长会对端到端的用户体验产生负面的影响 — 就像对简短查询的交互式分析一样,希望作业可以使用现有资源快速执行计算。
在 Session 模式下,集群生命周期独立于集群上运行的任何作业 并且资源在所有作业之间共享。应用程序模式为每个应用程序创建一个会话集群,并在集群上执行应用程序的方法。 因此,它具有更好的资源隔离,因为资源仅由从单个方法启动的作业使用。 这是以为每个应用程序启动专用集群为代价的。
package加载: 当Flink Session集群启动时,JobManager和TaskManager由Java classpath中的Flink框架类(Flink framework classes)进行启动加载。而通过session提交(REST或命令行方式)的job或应用程序由FlinkUserCodeClassLoader进行加载。
测试程序
1 | # |
测试效果
flink 总内存大小 Total Process Memory
jobmanager.memory.flink.size
检查点存储目录(本地文件系统或 HDFS/S3)
state.checkpoints.dir: s3p://s3_path_xxx/pro-oci-flink-cluster/completed-jobs/
#==============================================================================
Fault tolerance and checkpointing
#==============================================================================
state.backend.type: rocksdb
RocksDB 本地数据存储目录(每个 TaskManager)
state.backend.rocksdb.localdir: /data/flink-data/rocksdb/data
(可选)启用检查点,设置间隔(毫秒)
execution.checkpointing.interval: 60000
(可选)优化 RocksDB 性能
state.backend.rocksdb.memory-managed: true state.backend.rocksdb.block-cache-size: 256m state.backend.rocksdb.write-cache-size: 64m state.backend.rocksdb.compaction.style: leveled state.backend.rocksdb.thread.num: 4
#==============================================================================
Rest & web frontend
#==============================================================================
The port to which the REST client connects to. If rest.bind-port has
not been specified, then the server will bind to this port as well.
rest.port: 18081
The address to which the REST client will connect to
rest.address: 10.21.100.85
Port range for the REST and web server to bind to.
#rest.bind-port: 8080-8090
The address that the REST & web server binds to
By default, this is localhost, which prevents the REST & web server from
being able to communicate outside of the machine/container it is running on.
To enable this, set the bind address to one that has access to outside-facing
network interface, such as 0.0.0.0.
rest.bind-address: 0.0.0.0
#==============================================================================
Fault tolerance and checkpointing
#==============================================================================
web.submit.enable: false
web.cancel.enable: true
#==============================================================================
Advanced
#==============================================================================
io.tmp.dirs: /data/flink-data/tmp
#==============================================================================
HistoryServer
#==============================================================================
jobmanager.archive.fs.dir: s3p://s3_path_xxx/pro-oci-flink-cluster/completed-jobs/
The address under which the web-based HistoryServer listens.
historyserver.web.address: 0.0.0.0
The port under which the web-based HistoryServer listens.
historyserver.web.port: 8082
Comma separated list of directories to monitor for completed jobs.
historyserver.archive.fs.dir: s3p://s3_path_xxx/pro-oci-flink-cluster/historyserver-archive-fs-dir/
Interval in milliseconds for refreshing the monitored directories.
#historyserver.archive.fs.refresh-interval: 10000
s3.access-key: xxxx s3.secret-key: xxxx
jobmanager.rpc.address: 10.21.100.85 jobmanager.rpc.port: 6123 jobmanager.bind-host: 0.0.0.0
taskmanager.bind-host: 0.0.0.0 taskmanager.memory.process.size: 50gb taskmanager.numberOfTaskSlots: 64 parallelism.default: 8
jobmanager.execution.failover-strategy: region rest.port: 8081 rest.address: 10.21.100.190 #rest.bind-address: 10.21.100.190
jobmanager.archive.fs.dir: /data/jobmanager-task io.tmp.dirs: /data/flink-data/
blob.server.port: 6124 query.server.port: 6125
启用 ZooKeeper HA
high-availability: zookeeper
ZooKeeper 集群地址
high-availability.zookeeper.quorum: 10.21.100.88:2181,10.21.100.46:2181,10.21.100.211:2181
HA 元数据存储路径(S3)
high-availability.storageDir: s3p://s3_path_xxx/pro-oci-flink-cluster/flink-ha/
ZooKeeper 根路径(可选,隔离 Flink 数据)
high-availability.zookeeper.path.root: /flink
集群唯一标识(避免多集群冲突)
high-availability.cluster-id: flink-session-cluster-oci-01
'/flink-oci-01/flink-session-cluster-01' as Zookeeper namespace. ${high-availability.zookeeper.path.root} + ${high-availability.cluster-id}
ha
high-availability.type: zookeeper high-availability.storageDir: hdfs:///flink/ha/ high-availability.zookeeper.quorum: 10.21.100.88:2181,10.21.100.46:2181,10.21.100.211:2181
high-availability.zookeeper.path.root:
metrics.reporter.prom.factory.class: org.apache.flink.metrics.prometheus.PrometheusReporterFactory
===>
bash -c ' cat > conf/flink-conf.yaml << EOF
s3.access-key: xxx s3.secret-key: xxxx
jobmanager.rpc.address: 10.21.100.45 jobmanager.rpc.port: 6123 jobmanager.bind-host: 0.0.0.0
#flink 进程总内存 jobmanager.memory.process.size: 11g #flink 总内存大小 Total Process Memory jobmanager.memory.flink.size: 6g jobmanager.memory.jvm-metaspace.size: 384m jobmanager.memory.jvm-overhead: 1g jobmanager.memory.off-heap.size: 128m # 默认值
taskmanager.bind-host: 0.0.0.0 taskmanager.memory.process.size: 26g taskmanager.numberOfTaskSlots: 8 parallelism.default: 8
jobmanager.execution.failover-strategy: region
rest.port: 8081 rest.address: 10.21.100.45
jobmanager.archive.fs.dir: /data/jobmanager-task io.tmp.dirs: /data/flink-data/
blob.server.port: 6124 query.server.port: 6125
启用 ZooKeeper HA
high-availability: zookeeper
ZooKeeper 集群地址
high-availability.zookeeper.quorum: 10.21.100.88:2181,10.21.100.46:2181,10.21.100.211:2181
HA 元数据存储路径(S3)
high-availability.storageDir: s3p://s3_path_xxx/pro-oci-flink-cluster/flink-ha/
ZooKeeper 根路径(可选,隔离 Flink 数据)
high-availability.zookeeper.path.root: /flink
集群唯一标识(避免多集群冲突)
high-availability.cluster-id: flink-session-cluster-oci-prod-01
metrics
port 9249
metrics.reporter.prom.factory.class: org.apache.flink.metrics.prometheus.PrometheusReporterFactory
EOF'
1 | bin/flink run -m 127.0.0.1:8081 -c org.apache.flink.examples.java.wordcount.WordCount \ |
遇到的问题记录
taskManager slot 耗尽
1 |
|
1 | ... |
添加这个配置:
1 | cluster.fine-grained-resource-management.enabled: true |
为了启用细粒度的资源管理配置,需要将 cluster.fine-grained-resource-management.enabled 的值设置为 true。 没有该配置,Flink 运行 job 时并不能按照你指定的资源需求分配 slots,并且 job 会失败抛出异常。
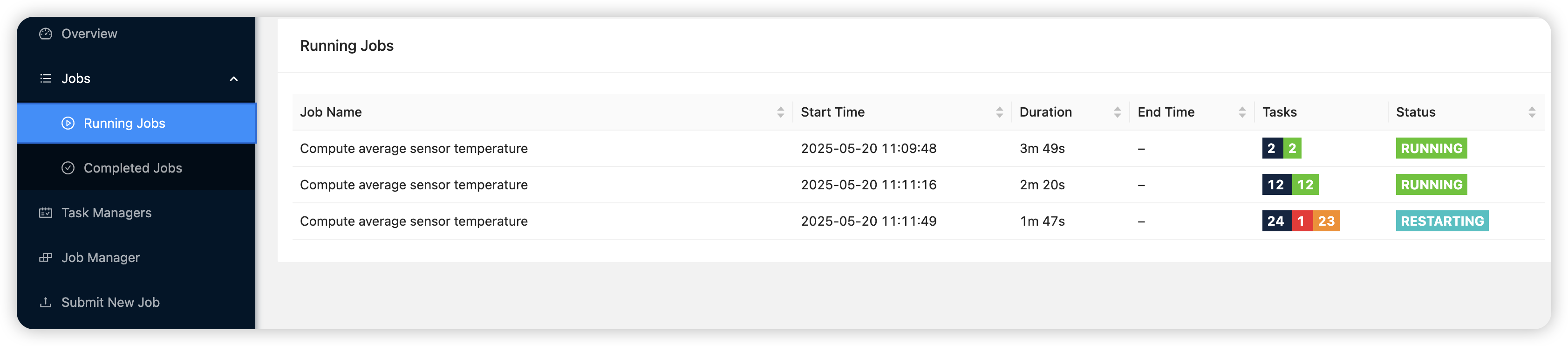
- 生产环境下,需要对集群进行扩容(增加TaskManger 节点)
- Title: Flink standalone session cluster 安装与配置
- Author: Ordiy
- Created at : 2025-01-01 00:00:00
- Updated at : 2026-03-23 15:48:10
- Link: https://ordiy.github.io/posts/2025-flink-session-mode-cluster-install/
- License: This work is licensed under CC BY-NC-SA 4.0.