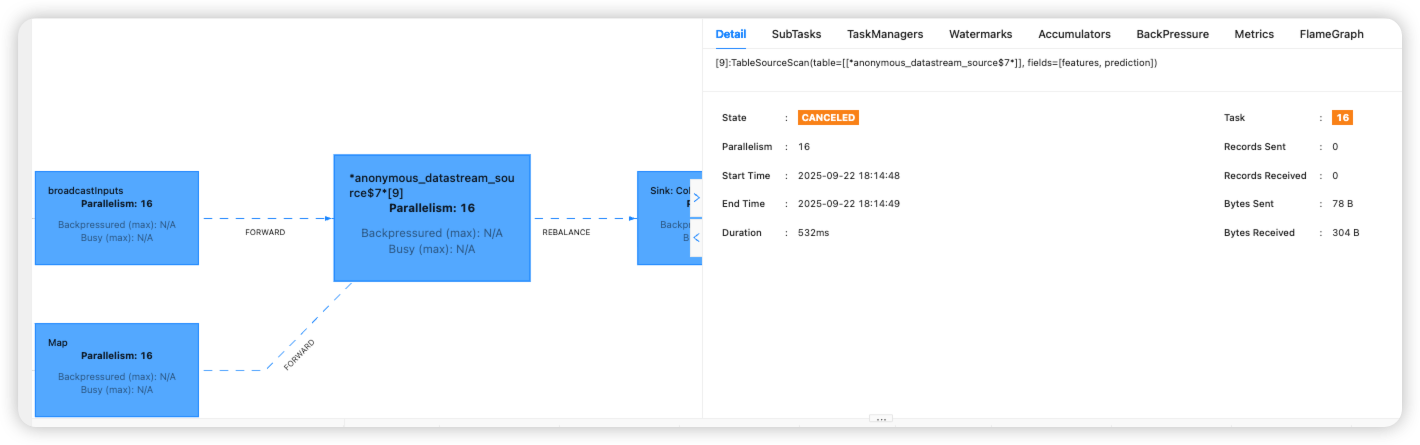
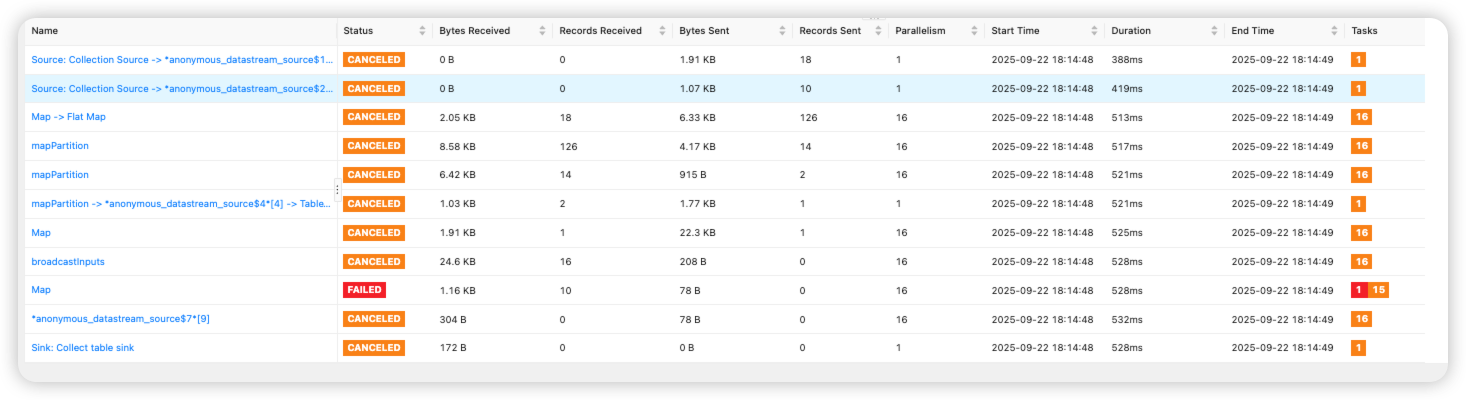
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
|
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.ml.classification.naivebayes.NaiveBayes;
import org.apache.flink.ml.classification.naivebayes.NaiveBayesModel;
import org.apache.flink.ml.linalg.DenseVector;
import org.apache.flink.ml.linalg.Vectors;
import org.apache.flink.runtime.state.hashmap.HashMapStateBackend;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
import java.util.concurrent.TimeUnit;
public class NaiveBayesTestMe {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(16);
env.setStateBackend(new HashMapStateBackend());
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3,
org.apache.flink.api.common.time.Time.of(20, TimeUnit.SECONDS)));
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env);
DataStream<Row> trainStream =
env.fromElements(
Row.of(Vectors.dense(59,1,3,3,3,3,6),0),
Row.of(Vectors.dense(12,1,1,1,3,1,4),0),
Row.of(Vectors.dense(14,1,4,2,1,2,4),0),
Row.of(Vectors.dense(80,1,1,1,1,1,4),0),
Row.of(Vectors.dense(14,1,2,2,1,2,5),0),
Row.of(Vectors.dense(25,1,2,2,1,2,4),0),
Row.of(Vectors.dense(35,1,2,2,1,2,4),0),
Row.of(Vectors.dense(42,1,8,2,3,1,15),0),
Row.of(Vectors.dense(7,1,1,1,1,1,4),0),
Row.of(Vectors.dense(4,1,0,2,2,1,1),1),
Row.of(Vectors.dense(2,1,0,2,2,1,1),1),
Row.of(Vectors.dense(2,1,0,2,2,1,1),1),
Row.of(Vectors.dense(4,1,0,2,2,1,1),1),
Row.of(Vectors.dense(2,1,0,2,2,1,1),1),
Row.of(Vectors.dense(4,1,0,2,2,1,1),1),
Row.of(Vectors.dense(2,1,0,2,2,1,1),1),
Row.of(Vectors.dense(4,1,0,2,2,1,1),1),
Row.of(Vectors.dense(5,1,0,2,2,1,1),1)
);
Table trainTable = tEnv.fromDataStream(trainStream).as("features", "label");
DataStream<Row> predictStream =
env.fromElements(
Row.of(Vectors.dense(6,1,3,2,1,2,4)),
Row.of(Vectors.dense(23,1,4,2,1,2,4 )),
Row.of(Vectors.dense(45,1,2,2,1,2,4 )),
Row.of(Vectors.dense(32,1,4,3,2,2,9 )),
Row.of(Vectors.dense(6,1,1,1,1,1,5 )),
Row.of(Vectors.dense(18,1,1,1,1,1,3 )),
Row.of(Vectors.dense(14,1,1,1,1,1,2 )),
Row.of(Vectors.dense(30,1,2,2,1,2,5 )),
Row.of(Vectors.dense(6,1,2,1,2,1,4 )),
Row.of(Vectors.dense(19,1,2,2,1,2,2 ))
);
Table predictTable = tEnv.fromDataStream(predictStream).as("features");
NaiveBayes naiveBayes =
new NaiveBayes()
.setSmoothing(1.0)
.setFeaturesCol("features")
.setLabelCol("label")
.setPredictionCol("prediction")
.setModelType("multinomial");
NaiveBayesModel naiveBayesModel = naiveBayes.fit(trainTable);
Table outputTable = naiveBayesModel.transform(predictTable)[0];
outputTable.execute().print();
env.execute("my_job");
}
}
|