Learn "AI Scaling Law"
前言
 AI模型的训练通常分为预训练(学习通用知识)、后训练(微调和强化学习,例如RLHF)和测试时计算(推理阶段的额外算力)。
AI模型的训练通常分为预训练(学习通用知识)、后训练(微调和强化学习,例如RLHF)和测试时计算(推理阶段的额外算力)。
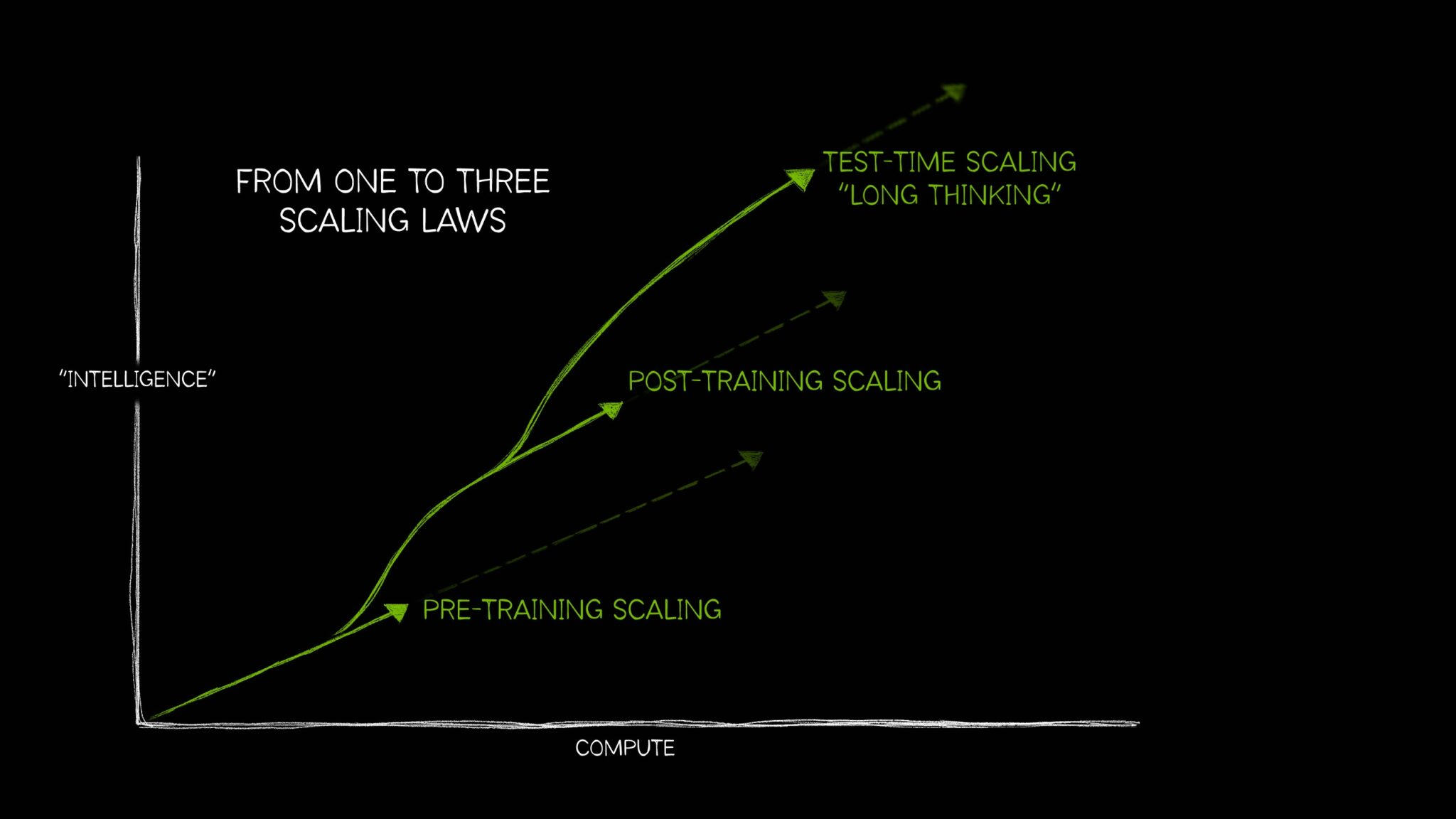
AI 已经发展到需要三个不同的定律来描述以不同方式应用计算资源如何影响模型性能。这些 AI 扩展定律(训练前扩展(pretraining scaling)、训练后扩展(post-training scaling)和测试时扩展 (test-time scaling,),也称为长思维)共同反映了该领域如何随着在各种日益复杂的 AI 用例中使用额外计算的技术而发展。
测试时扩展的兴起(在推理时应用更多计算以提高准确性)使 AI 推理模型成为可能,AI 推理模型是一类新的大型语言模型 (LLM),可以执行多次推理传递来解决复杂问题,同时描述解决任务所需的步骤。测试时扩展需要大量的计算资源来支持 AI 推理,这将进一步推动对加速计算的需求。
以Grok3模型为例子(数据为推测) 比如grok3 模型:
- Pre-training(预训练)
- 预训练通常是算力消耗最大的阶段,用于构建模型的基础知识。Grok 3的预训练据称使用了10倍于Grok 2的算力。假设Grok 2预训练用了约5000万GPU小时(基于15,000 H100 GPU和数月训练的粗略估计),那么Grok 3的预训练可能消耗了5亿GPU小时左右。这可能占总算力的60%-80%,因为xAI强调了大规模预训练以提升基础模型能力。
- Post-training(后训练)
- 后训练包括微调和强化学习(RL),Grok 3通过大规模RL优化了推理能力(例如自我纠错和多步推理)。根据业界经验(如Chinchilla Scaling Law),后训练算力通常比预训练少,但Grok 3的强化学习规模“史无前例”,可能占总算力的20%-30%。假设总算力为7亿GPU小时,后训练可能用了1.5亿-2亿GPU小时。
- Test-time(测试时)
- 测试时计算是指推理阶段的额外算力消耗,例如Grok 3的“Think”模式允许模型花费数秒到数分钟思考问题。这种算力按需分配,且与训练阶段不同,主要取决于用户使用量和任务复杂度。以10万用户每天平均使用1小时推理计算为例,每用户可能消耗0.1-1 GPU小时,总计每天1万-10万GPU小时。但这不是固定成本,而是运行时的动态消耗。
什么是预训练扩展?
预训练扩展是 AI 开发的原始定律。它表明,通过增加训练数据集的大小、模型参数数量和计算资源,开发人员可以预期模型智能和准确性的改进是可预测的。
这三个元素(数据、模型大小、计算)中的每一个都是相互关联的。根据本研究论文中概述的训练前扩展定律,当较大的模型输入更多数据时,模型的整体性能会提高。为了实现这一目标,开发人员必须扩展其计算,从而需要强大的加速计算资源来运行那些更大的训练工作负载。
这种预训练扩展原则导致了实现突破性功能的大型模型。它还刺激了模型架构的重大创新,包括十亿和万亿参数 transformer 模型的兴起、专家模型的混合和新的分布式训练技术——所有这些都需要大量的计算。
随着人类继续产生越来越多的多模态数据,这些文本、图像、音频、视频和传感器信息宝库将用于训练强大的未来 AI 模型。
什么是训练后扩展?
预训练大型基础模型并不适合所有人,它需要大量投资、熟练的专家和数据集。但是,一旦组织预先训练并发布了模型,他们就会使其他人能够使用其预训练模型作为适应自己应用程序的基础,从而降低了 AI 采用的门槛。
这种培训后过程推动了企业和更广泛的开发人员社区对加速计算的额外累积需求。流行的开源模型可以有成百上千个衍生模型,这些模型在众多领域中进行了训练。
为各种使用案例开发这个衍生模型生态系统可能需要比预训练原始基础模型多 30 倍左右的计算。 后训练技术可以进一步提高模型的特异性和与组织所需用例的相关性。预训练就像将 AI 模型送到学校学习基本技能,而后训练则通过适用于其预期工作的技能来增强模型。例如,LLM 可以接受后期培训以处理情感分析或翻译等任务,或者理解特定领域的术语,例如医疗保健或法律。
训练后缩放定律假设,使用包括微调(Fine-tuning)、修剪(Distillation)、量化(Quantization)、蒸馏(Distillation)、强化学习(Reinforcement Learning)和合成数据增强(Synthetic Data Augmentation)在内的技术,预训练模型的性能可以进一步提高计算效率、准确性或领域特异性。
- Fine-tuning 使用额外的训练数据为特定领域和应用程序定制 AI 模型。这可以使用组织的内部数据集或使用成对的示例模型输入和输出来完成。
- Distillation 需要一对 AI 模型:一个大型、复杂的教师模型和一个轻量级的学生模型。在最常见的蒸馏技术(称为离线蒸馏)中,学生模型学习模拟预先训练的教师模型的输出。
- 强化学习 (RL) 是一种机器学习技术,它使用奖励模型来训练代理做出与特定使用案例一致的决策。代理旨在做出决策,在与环境交互时,随着时间的推移实现累积奖励的最大化,例如,聊天机器人 LLM 会因用户的“竖起大拇指”反应而得到积极强化。这种技术被称为来自人类反馈的强化学习 (RLHF)。另一种较新的技术,即来自 AI 反馈的强化学习 (RLAIF),它使用来自 AI 模型的反馈来指导学习过程,从而简化训练后的工作。
- n 次最佳采样从语言模型生成多个输出,并根据奖励模型选择具有最高奖励分数的输出。它通常用于在不修改模型参数的情况下提高 AI 的输出,从而为使用强化学习进行微调提供了一种替代方案。
- 搜索方法在选择最终输出之前探索一系列可能的决策路径。这种后训练技术可以迭代地改进模型的响应。
为了支持后训练,开发人员可以使用合成数据来增强或补充他们的微调数据集。使用 AI 生成的数据补充真实数据集可以帮助模型提高其处理原始训练数据中代表性不足或缺失的边缘情况的能力。
什么是测试时缩放?
LLM 生成对输入提示的快速响应。虽然此过程非常适合获得简单问题的正确答案,但当用户提出复杂查询时,它可能无法正常工作。回答复杂问题(代理 AI 工作负载的一项基本功能)需要 LLM 在提出答案之前对问题进行推理。
这与大多数人的思维方式相似——当被要求加二加二时,他们会立即给出答案,而无需讨论加法或整数的基本原理。但是,如果当场被要求制定一项可以使公司利润增加 10% 的商业计划,一个人可能会通过各种选项进行推理并提供多步骤的答案。
测试时缩放,也称为长思维,发生在推理期间。使用这种技术的模型在推理过程中分配了额外的计算工作,使它们能够在得出最佳答案之前通过多个可能的响应进行推理,而不是快速生成对用户提示的一次性答案的传统 AI 模型。
对于为开发人员生成复杂的自定义代码等任务,此 AI 推理过程可能需要几分钟甚至几小时,并且与传统 LLM 上的单个推理传递相比,很容易需要超过 100 倍的计算来处理具有挑战性的查询,而传统 LLM 极不可能在第一次尝试时就产生正确答案来响应复杂问题。
这种测试时计算功能使 AI 模型能够探索问题的不同解决方案,并将复杂的请求分解为多个步骤,在许多情况下,在用户推理时向用户展示他们的工作。研究发现,当 AI 模型被赋予需要几个推理和规划步骤的开放式提示时,测试时缩放会产生更高质量的响应。
测试时计算方法有多种方法,包括:
- 思路提示(Chain-of-thought prompting):将复杂问题分解为一系列更简单的步骤。
- Sampling with majority voting(多数投票抽样):生成对同一提示的多个响应,然后选择最频繁重复的答案作为最终输出。
- 搜索:探索和评估响应的树状结构中存在的多个路径。
训练后方法(如 Best-of-n 采样)也可用于推理过程中的长时间思考,以根据人类偏好或其他目标优化响应。

测试时扩展通过分配额外的计算来改进 AI 推理来增强推理,使模型能够有效地解决复杂的多步骤问题.
测试时扩展如何实现 AI 推理
测试时计算的兴起使 AI 能够为复杂的开放式用户查询提供合理、有用且更准确的响应。这些功能对于自主代理 AI 和实体 AI physical AI](https://www.nvidia.com/en-us/glossary/generative-physical-ai/) 应用程序预期的详细、多步骤推理任务至关重要。在各行各业,他们可以通过为用户提供功能强大的助手来加速他们的工作,从而提高效率和生产力。
在医疗保健领域,模型可以使用测试时间缩放来分析大量数据并推断疾病将如何发展,以及根据药物分子的化学结构预测新疗法可能引起的潜在并发症。或者,它可以梳理临床试验数据库,提出与个人疾病状况相匹配的选项,分享其关于不同研究的利弊的推理过程。
在零售和供应链物流领域,长远思考有助于做出应对近期运营挑战和长期战略目标所需的复杂决策。推理技术可以通过同时预测和评估多个场景来帮助企业降低风险并应对可扩展性挑战,从而实现更准确的需求预测、简化供应链旅行路线以及与组织的可持续发展计划相一致的采购决策。
对于全球企业,这项技术可用于起草详细的商业计划,生成复杂的代码来调试软件,或优化送货卡车、仓库机器人和机器人出租车的旅行路线。
AI 推理模型正在迅速发展。OpenAI o1-mini 和 o3-mini、DeepSeek R1 和 Google DeepMind 的 Gemini 2.0 Flash Thinking 都已在过去几周推出,预计很快就会推出更多新型号。
像这样的模型需要更多的计算来在推理过程中进行推理,并为复杂问题生成正确的答案,这意味着企业需要扩展其加速计算资源,以提供能够支持复杂问题解决、编码和多步骤规划的下一代 AI 推理工具。
参考
- Title: Learn "AI Scaling Law"
- Author: Ordiy
- Created at : 2025-03-26 18:08:00
- Updated at : 2026-03-23 15:48:10
- Link: https://ordiy.github.io/posts/2025-03-learnging-ai-scaling-laws/
- License: This work is licensed under CC BY-NC-SA 4.0.