Spark输出处理-文本数据
需求
- 提取文本日志中指定的字段信息
- 对字段进行筛选排序
文本数据
- 以
tuna tsinghua的网络数据为例子:
1 | $fake_remote_addr - $remote_user [$time_local] "$request" $status $body_bytes_sent "$sent_http_content_type" "$http_referer" "$http_user_agent" - $scheme |
格式:
1 | 203.119.172.233 - - [15/Apr/2024:00:19:31 +0800] "GET /simple/pip/ HTTP/1.1" 403 1513 "text/html" "-" "pip/21.3.1 {\x22ci\x22:null,\x22cpu\x22:\x22x86_64\x22,\x22distro\x22:{\x22id\x22:\x22Paladin\x22,\x22libc\x22:{\x22lib\x22:\x22glibc\x22,\x22version\x22:\x222.17\x22},\x22name\x22:\x22Alibaba Group Enterprise Linux Server\x22,\x22version\x22:\x227.2\x22},\x22implementation\x22:{\x22name\x22:\x22CPython\x22,\x22version\x22:\x223.7.5rc1\x22},\x22installer\x22:{\x22name\x22:\x22pip\x22,\x22version\x22:\x2221.3.1\x22},\x22openssl_version\x22:\x22OpenSSL 1.0.2k-fips 26 Jan 2017\x22,\x22python\x22:\x223.7.5rc1\x22,\x22setuptools_version\x22:\x2241.2.0\x22,\x22system\x22:{\x22name\x22:\x22Linux\x22,\x22release\x22:\x224.19.91-011.ali4000.alios7.x86_64\x22}}" - https |
处理数据
1 |
|
运行:
1 | mvn package -Dmaven.test.skip=true && \ |
执行结果:
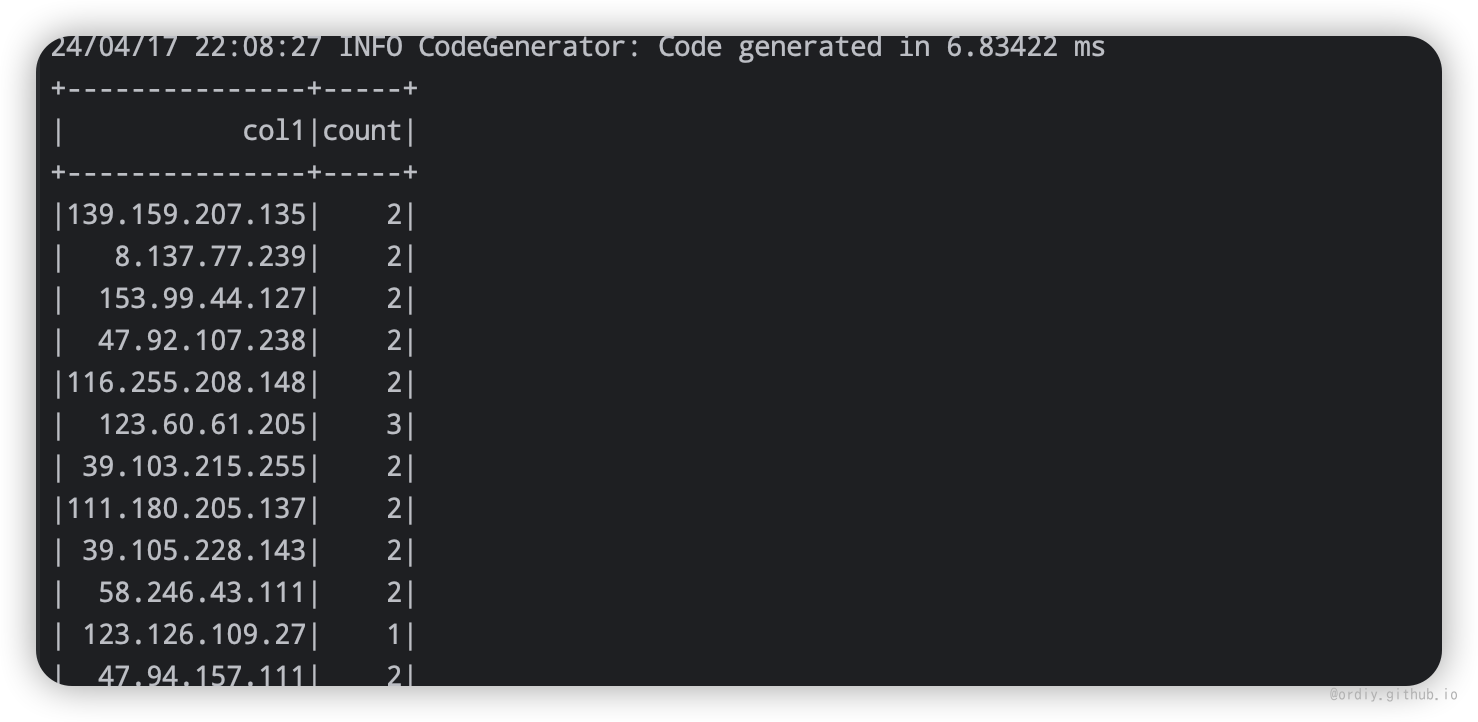
文本数据
https://mirrors.tuna.tsinghua.edu.cn/news/release-logs/ https://mirrors.tuna.tsinghua.edu.cn/logs/nanomirrors/
- Title: Spark输出处理-文本数据
- Author: Ordiy
- Created at : 2022-04-17 19:11:47
- Updated at : 2026-03-23 15:48:10
- Link: https://ordiy.github.io/posts/2024-02-02-spark-txt-opt/
- License: This work is licensed under CC BY-NC-SA 4.0.
Comments