1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
| 24/04/17 16:35:23 INFO ResourceUtils: ==============================================================
24/04/17 16:35:23 INFO ResourceUtils: No custom resources configured for spark.driver.
24/04/17 16:35:23 INFO ResourceUtils: ==============================================================
24/04/17 16:35:23 INFO SparkContext: Submitted application: JavaWordCount
24/04/17 16:35:23 INFO ResourceProfile: Default ResourceProfile created, executor resources: Map(memory -> name: memory, amount: 1024, script: , vendor: , offHeap -> name: offHeap, amount: 0, script: , vendor: ), task resources: Map(cpus -> name: cpus, amount: 1.0)
24/04/17 16:35:23 INFO ResourceProfile: Limiting resource is cpu
24/04/17 16:35:23 INFO ResourceProfileManager: Added ResourceProfile id: 0
24/04/17 16:35:24 INFO SecurityManager: Changing view acls to: ordiy
24/04/17 16:35:24 INFO SecurityManager: Changing modify acls to: ordiy
24/04/17 16:35:24 INFO SecurityManager: Changing view acls groups to:
24/04/17 16:35:24 INFO SecurityManager: Changing modify acls groups to:
24/04/17 16:35:24 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: ordiy; groups with view permissions: EMPTY; users with modify permissions: ordiy; groups with modify permissions: EMPTY
24/04/17 16:35:24 INFO Utils: Successfully started service 'sparkDriver' on port 53452.
24/04/17 16:35:24 INFO SparkEnv: Registering MapOutputTracker
24/04/17 16:35:24 INFO SparkEnv: Registering BlockManagerMaster
24/04/17 16:35:24 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
24/04/17 16:35:24 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
24/04/17 16:35:24 INFO SparkEnv: Registering BlockManagerMasterHeartbeat
24/04/17 16:35:24 INFO DiskBlockManager: Created local directory at /private/var/folders/r6/15tb2r_n5y31w0pyr09vhk_40000gn/T/blockmgr-e3e399fa-a206-4028-9b59-f97169b169c2
24/04/17 16:35:24 INFO MemoryStore: MemoryStore started with capacity 434.4 MiB
24/04/17 16:35:24 INFO SparkEnv: Registering OutputCommitCoordinator
24/04/17 16:35:24 INFO JettyUtils: Start Jetty 0.0.0.0:4040 for SparkUI
24/04/17 16:35:24 INFO Utils: Successfully started service 'SparkUI' on port 4040.
24/04/17 16:35:25 INFO SparkContext: Added JAR file:/opt/ordiy/00_studiy_test/test-spark-env/target/test-spark-env-1.0-SNAPSHOT.jar at spark:
24/04/17 16:35:25 INFO StandaloneAppClient$ClientEndpoint: Connecting to master spark:
24/04/17 16:35:25 INFO TransportClientFactory: Successfully created connection to ordiy-mac.local/127.0.0.1:7077 after 51 ms (0 ms spent in bootstraps)
24/04/17 16:35:25 INFO StandaloneSchedulerBackend: Connected to Spark cluster with app ID app-20240417163525-0011
24/04/17 16:35:25 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 53457.
24/04/17 16:35:25 INFO NettyBlockTransferService: Server created on 192.168.1.66:53457
24/04/17 16:35:25 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
24/04/17 16:35:25 INFO StandaloneAppClient$ClientEndpoint: Executor added: app-20240417163525-0011/0 on worker-20240417120326-192.168.1.66-53612 (192.168.1.66:53612) with 16 core(s)
24/04/17 16:35:25 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, 192.168.1.66, 53457, None)
24/04/17 16:35:25 INFO StandaloneSchedulerBackend: Granted executor ID app-20240417163525-0011/0 on hostPort 192.168.1.66:53612 with 16 core(s), 1024.0 MiB RAM
24/04/17 16:35:25 INFO BlockManagerMasterEndpoint: Registering block manager 192.168.1.66:53457 with 434.4 MiB RAM, BlockManagerId(driver, 192.168.1.66, 53457, None)
24/04/17 16:35:25 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, 192.168.1.66, 53457, None)
24/04/17 16:35:25 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, 192.168.1.66, 53457, None)
24/04/17 16:35:25 INFO StandaloneAppClient$ClientEndpoint: Executor updated: app-20240417163525-0011/0 is now RUNNING
24/04/17 16:35:25 INFO StandaloneSchedulerBackend: SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.0
24/04/17 16:35:26 INFO SharedState: Setting hive.metastore.warehouse.dir ('null') to the value of spark.sql.warehouse.dir.
24/04/17 16:35:26 INFO SharedState: Warehouse path is 'file:/opt/ordiy/00_studiy_test/test-spark-env/spark-warehouse'.
24/04/17 16:35:27 INFO InMemoryFileIndex: It took 54 ms to list leaf files for 1 paths.
24/04/17 16:35:28 INFO StandaloneSchedulerBackend$StandaloneDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client:
24/04/17 16:35:28 INFO BlockManagerMasterEndpoint: Registering block manager 192.168.1.66:53464 with 434.4 MiB RAM, BlockManagerId(0, 192.168.1.66, 53464, None)
24/04/17 16:35:30 INFO FileSourceStrategy: Pushed Filters:
24/04/17 16:35:30 INFO FileSourceStrategy: Post-Scan Filters:
24/04/17 16:35:30 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 199.4 KiB, free 434.2 MiB)
24/04/17 16:35:30 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 34.3 KiB, free 434.2 MiB)
24/04/17 16:35:30 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 192.168.1.66:53457 (size: 34.3 KiB, free: 434.4 MiB)
24/04/17 16:35:30 INFO SparkContext: Created broadcast 0 from javaRDD at WordCounter.java:25
24/04/17 16:35:30 INFO FileSourceScanExec: Planning scan with bin packing, max size: 4194304 bytes, open cost is considered as scanning 4194304 bytes.
24/04/17 16:35:31 INFO SparkContext: Starting job: collect at WordCounter.java:33
24/04/17 16:35:31 INFO DAGScheduler: Registering RDD 6 (mapToPair at WordCounter.java:29) as input to shuffle 0
24/04/17 16:35:31 INFO DAGScheduler: Got job 0 (collect at WordCounter.java:33) with 1 output partitions
24/04/17 16:35:31 INFO DAGScheduler: Final stage: ResultStage 1 (collect at WordCounter.java:33)
24/04/17 16:35:31 INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage 0)
24/04/17 16:35:31 INFO DAGScheduler: Missing parents: List(ShuffleMapStage 0)
24/04/17 16:35:31 INFO DAGScheduler: Submitting ShuffleMapStage 0 (MapPartitionsRDD[6] at mapToPair at WordCounter.java:29), which has no missing parents
24/04/17 16:35:31 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 25.5 KiB, free 434.1 MiB)
24/04/17 16:35:31 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 11.7 KiB, free 434.1 MiB)
24/04/17 16:35:31 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 192.168.1.66:53457 (size: 11.7 KiB, free: 434.4 MiB)
24/04/17 16:35:31 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:1585
24/04/17 16:35:31 INFO DAGScheduler: Submitting 1 missing tasks from ShuffleMapStage 0 (MapPartitionsRDD[6] at mapToPair at WordCounter.java:29) (first 15 tasks are for partitions Vector(0))
24/04/17 16:35:31 INFO TaskSchedulerImpl: Adding task set 0.0 with 1 tasks resource profile 0
24/04/17 16:35:31 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0) (192.168.1.66, executor 0, partition 0, PROCESS_LOCAL, 8418 bytes)
24/04/17 16:35:31 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 192.168.1.66:53464 (size: 11.7 KiB, free: 434.4 MiB)
24/04/17 16:35:33 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 192.168.1.66:53464 (size: 34.3 KiB, free: 434.4 MiB)
24/04/17 16:35:33 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 2065 ms on 192.168.1.66 (executor 0) (1/1)
24/04/17 16:35:33 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
24/04/17 16:35:33 INFO DAGScheduler: ShuffleMapStage 0 (mapToPair at WordCounter.java:29) finished in 2.209 s
24/04/17 16:35:33 INFO DAGScheduler: looking for newly runnable stages
24/04/17 16:35:33 INFO DAGScheduler: running: Set()
24/04/17 16:35:33 INFO DAGScheduler: waiting: Set(ResultStage 1)
24/04/17 16:35:33 INFO DAGScheduler: failed: Set()
24/04/17 16:35:33 INFO DAGScheduler: Submitting ResultStage 1 (ShuffledRDD[7] at reduceByKey at WordCounter.java:31), which has no missing parents
24/04/17 16:35:33 INFO MemoryStore: Block broadcast_2 stored as values in memory (estimated size 5.2 KiB, free 434.1 MiB)
24/04/17 16:35:33 INFO MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 2.9 KiB, free 434.1 MiB)
24/04/17 16:35:33 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on 192.168.1.66:53457 (size: 2.9 KiB, free: 434.4 MiB)
24/04/17 16:35:33 INFO SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:1585
24/04/17 16:35:33 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 1 (ShuffledRDD[7] at reduceByKey at WordCounter.java:31) (first 15 tasks are for partitions Vector(0))
24/04/17 16:35:33 INFO TaskSchedulerImpl: Adding task set 1.0 with 1 tasks resource profile 0
24/04/17 16:35:33 INFO TaskSetManager: Starting task 0.0 in stage 1.0 (TID 1) (192.168.1.66, executor 0, partition 0, NODE_LOCAL, 7627 bytes)
24/04/17 16:35:33 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on 192.168.1.66:53464 (size: 2.9 KiB, free: 434.4 MiB)
24/04/17 16:35:33 INFO MapOutputTrackerMasterEndpoint: Asked to send map output locations for shuffle 0 to 192.168.1.66:53460
24/04/17 16:35:33 INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID 1) in 425 ms on 192.168.1.66 (executor 0) (1/1)
24/04/17 16:35:33 INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
24/04/17 16:35:33 INFO DAGScheduler: ResultStage 1 (collect at WordCounter.java:33) finished in 0.435 s
24/04/17 16:35:33 INFO DAGScheduler: Job 0 is finished. Cancelling potential speculative or zombie tasks for this job
24/04/17 16:35:33 INFO TaskSchedulerImpl: Killing all running tasks in stage 1: Stage finished
24/04/17 16:35:33 INFO DAGScheduler: Job 0 finished: collect at WordCounter.java:33, took 2.712365 s
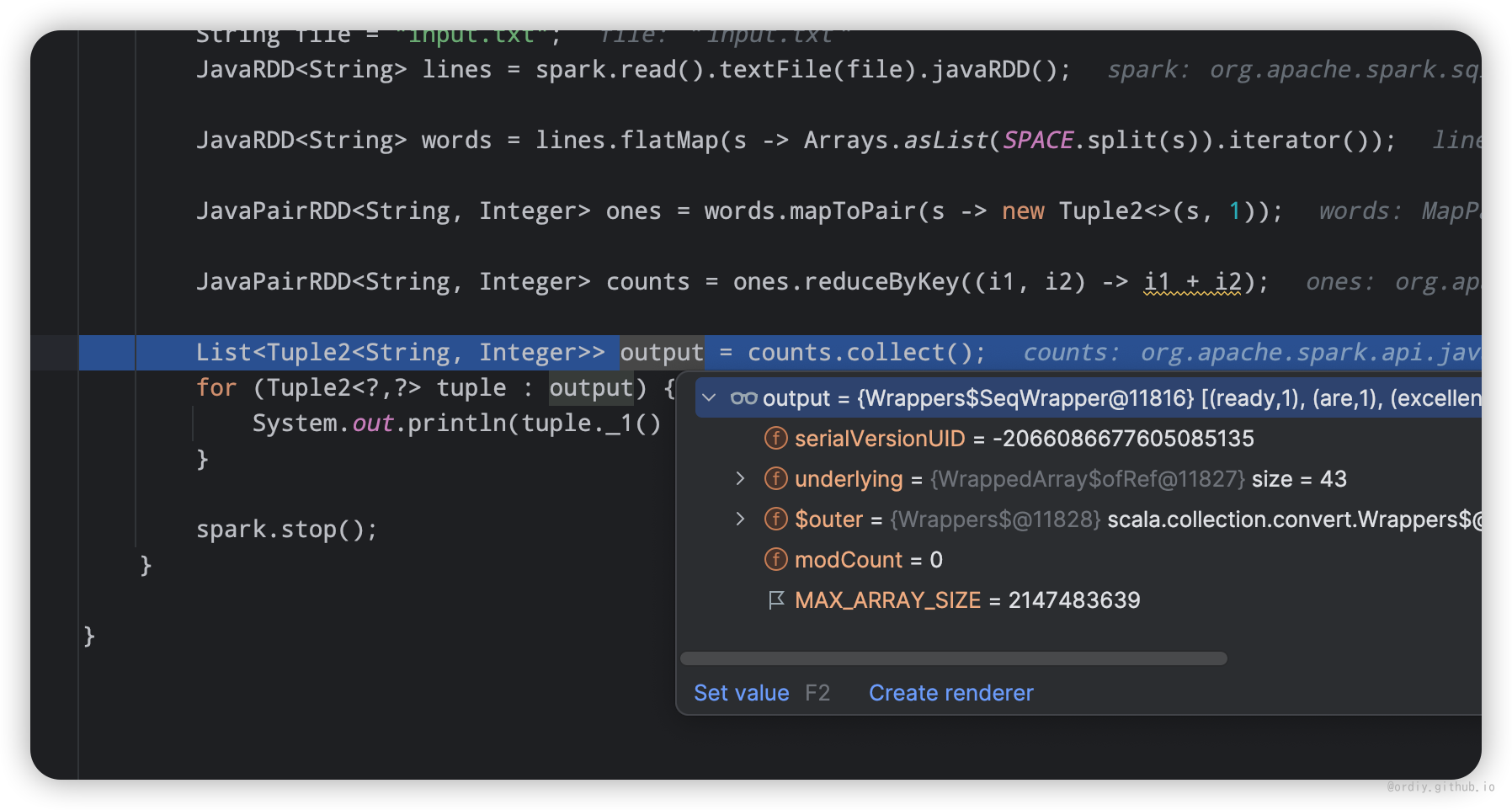
ready: 1
are: 1
excellent: 1
languages.: 1
find: 2
Python: 1
author: 1
Shubham: 1
you: 1
is: 2
about: 1
can: 1
name: 1
a: 1
am: 1
on: 1
Big: 3
many: 1
JournalDev: 3
.: 1
lessons: 3
some: 1
Java,: 1
I: 1
to: 2
written: 1
: 1
at: 2
more: 1
pieces: 1
of: 1
website: 1
Data.: 1
Data,: 1
my: 1
great: 2
Hello,: 1
difficult: 1
but: 1
and: 2
Data: 1
,: 1
Programming: 1
24/04/17 16:36:45 INFO SparkContext: SparkContext is stopping with exitCode 0.
24/04/17 16:36:45 INFO SparkUI: Stopped Spark web UI at http:
|