HBase Region Move 批量操作
背景说明
公司的HBase集群部分RegionServer需要进行重启, 每个RegionServer上有1000个左右的RegionServer,单表的容量1T+, 为将RegionServer重启的过程对业务RPC的影响降低最少,需要在重启前将Region移到别的RegionServer上。
HBase Region 和 Region move 说明
- HBase Region HBase 表(Table)根据 rowkey 的范围被水平拆分成若干个 region。每个 region 都包含了这个region 的 start key 和 end key 之间的所有行(row)。Regions 被分配给集群中的某些节点来管理,即 Region Server,由它们来负责处理数据的读写请求。 Region 目录结构:
1 | Table (HBase table) |
注:Region是数据表的分片,是RegionServer管理的主要对象。一个Region由一个或多个Store构成(Store数量取决于Column famliy 的个数)。
region move 过程 Region move 是一个region assign的过程(这里还没找到具体的资料,后续确定了再补充)

使用场景 主要用于RPC 流量和Region都非常多的HBase集群,避免在RegionServer重启时,部分Region不可用的问题。比如需要迁移/增加ZK节点需要重启RegionServer/DataNode等,但是又要保证业务不受影响。 Client Scan获取Region信息示意图:

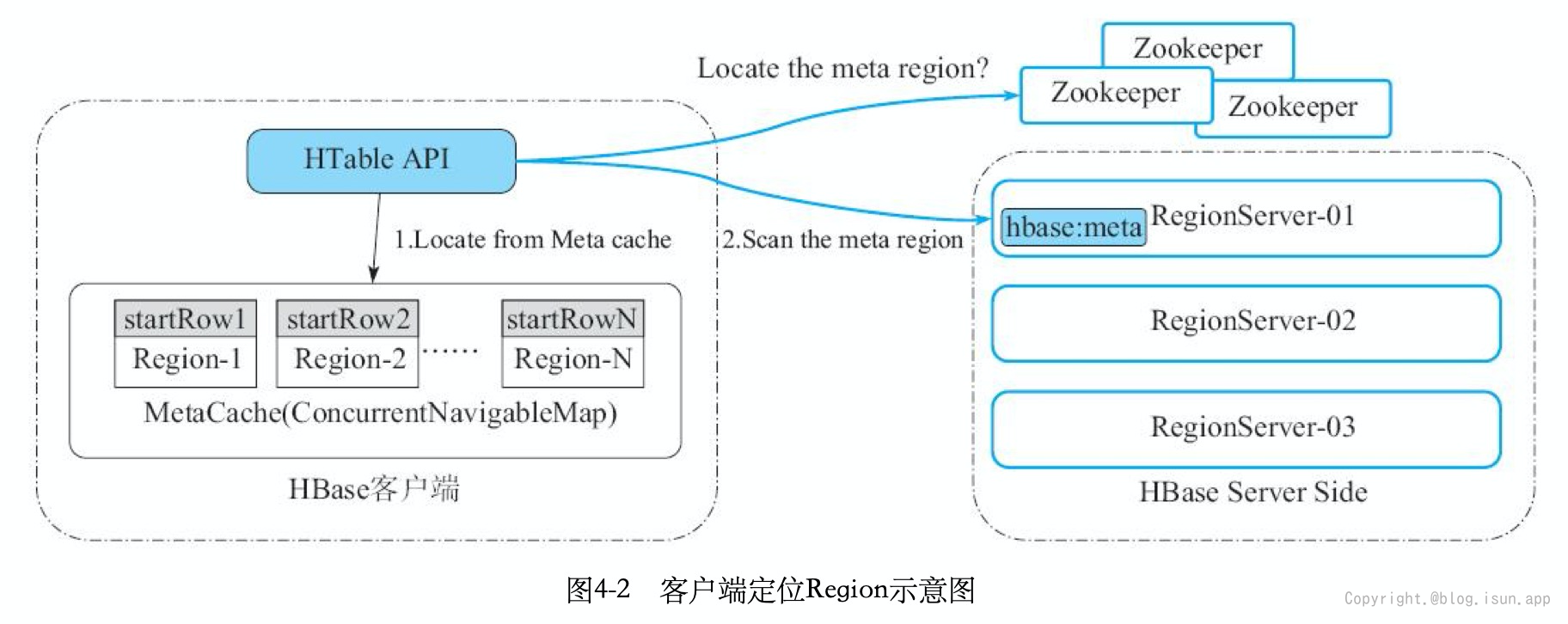
Region move 操作
HBase region 信息获取
HBase Region 信息存储在hbase:mata表中,具体可以通过以下方式获取:
1 | #hbase2.X |
*HBase2.x 与HBase1.x 的RegionInfo格式是不一样的,这里需要注意。
Region blance switch
关闭region的自动均衡策略:
1 | hbase> balance_switch false |
HBase region 批量操作
将Node99的Region其全部挪动到指定node235
1 | cat << EOF > node99-shell.sh |
总结
提前移动Region和不移动Region,本地化率变化对比:
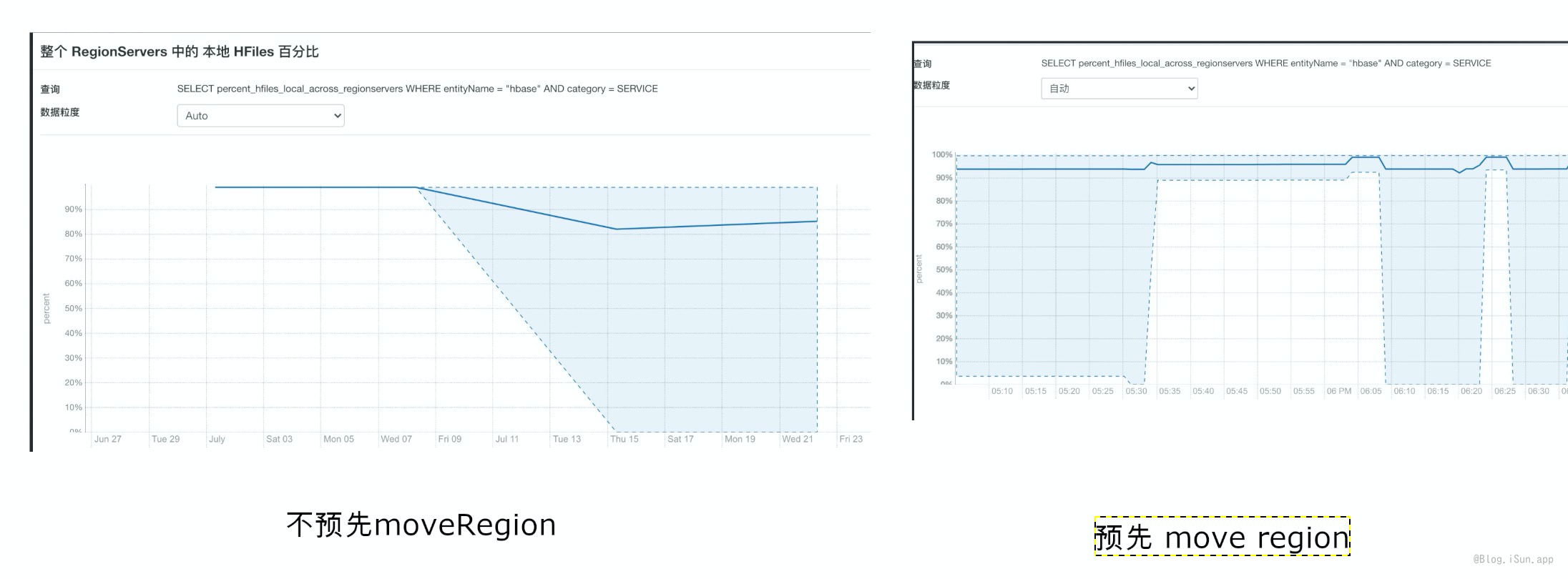 预先move Region,集群的HFile本地化率,更加稳定。
Region 的状态机变换机制复杂,这里只是进行了一个简要的介绍,侧重在于应用层面。
预先move Region,集群的HFile本地化率,更加稳定。
Region 的状态机变换机制复杂,这里只是进行了一个简要的介绍,侧重在于应用层面。
参考文献
- 《HBase原理与实践》
- HBase Book Guide Regions
- Title: HBase Region Move 批量操作
- Author: Ordiy
- Created at : 2021-06-23 17:15:58
- Updated at : 2026-03-23 15:48:10
- Link: https://ordiy.github.io/posts/2021-06-11-hbase-region-move-md/
- License: This work is licensed under CC BY-NC-SA 4.0.
Comments