HBase HFile 基本概念
HFile 简介
HFile参考BigTable的SSTable和Hadoop的TFile实现,用于MemStore中数据落盘之后会形成一个或者多个文件写入HDFS。HFile JARA HBASE-61
HFile 结构
HFile 逻辑结构
以HFile V2为例,HFile的逻辑结构:
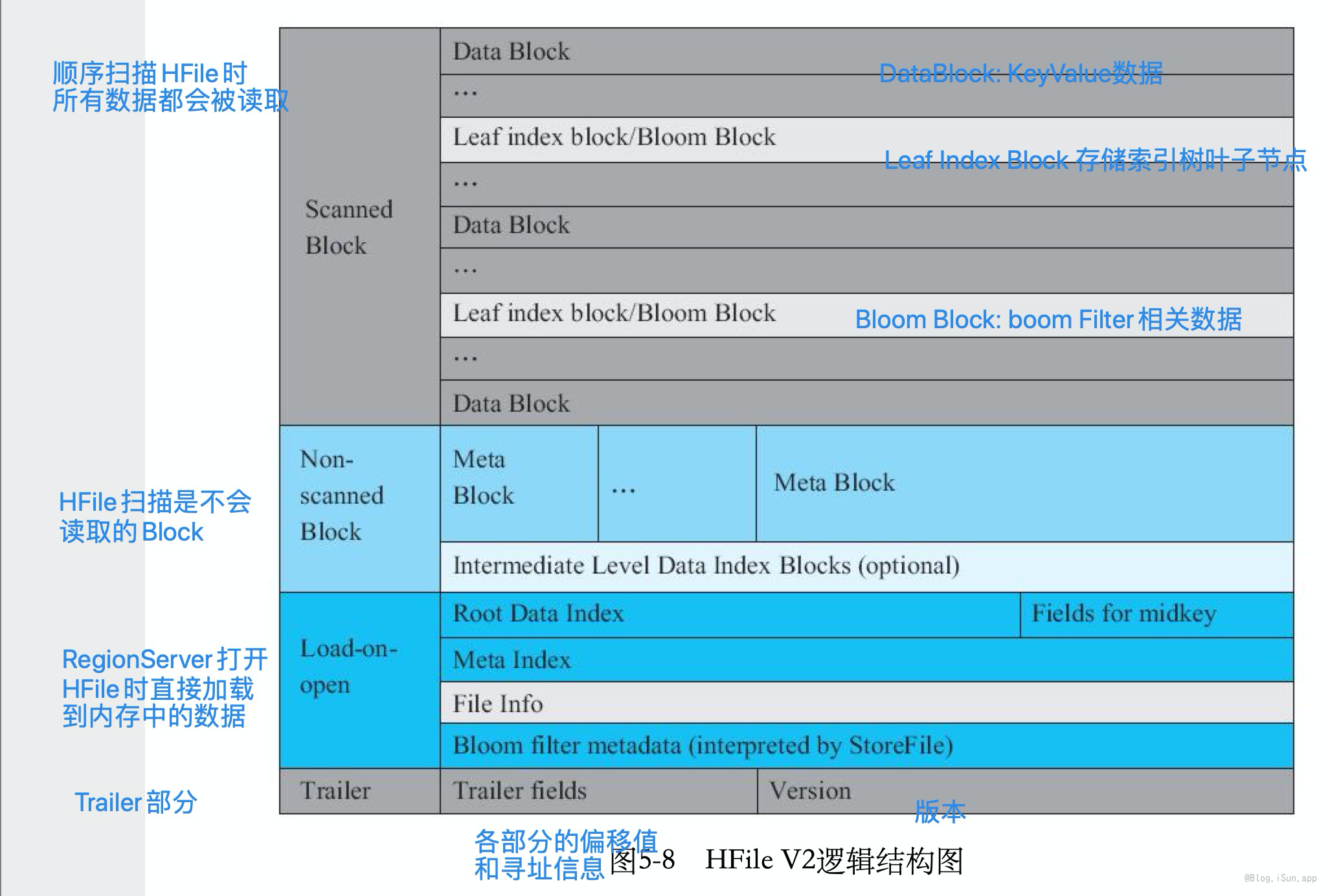
HFile 物理结构
以HFile V2为例,HFile的物理结构:
HFile各种不同类型的Block构成,在HBase DDL建表语句中的BLOCKSIZE => '65536',表示Block的大小。

虽然HFile的Block Type有多种,但是每个Block的数据结构都是一样的(便于存储,遍历?),Block结构:
 又的数据可能会存储在多个HFile Block上。
又的数据可能会存储在多个HFile Block上。
HFile Block 的BlockType 类型:

- 参考更多: HFile v1 & HFile v2
HFile V2 feature
HFile V2在Boolm Fileter上增加了位数组拆分功能,可以按照Key拆分
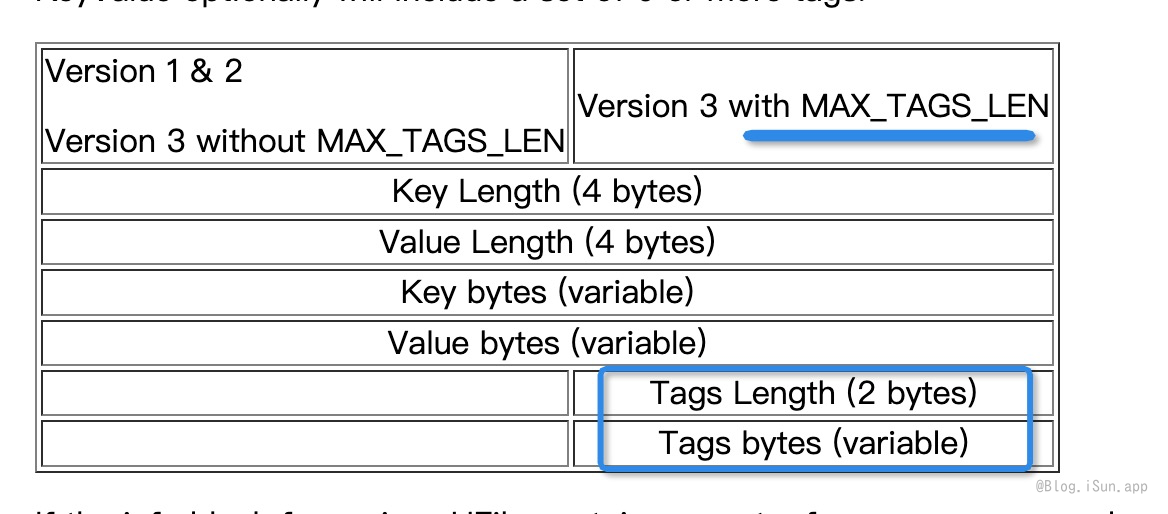
HFile V3 feature
HFile V3与HFile基本相同,只是增加了对cell的标签功能支持,cell标签为其它与安全相关的功能(cell 级别的ACL和单元级别可见性)提供提供实现框架。 实现: cell关联0个或多个可见性标签,再将可见性与用户关联起来。(一个实践案例)
| additional info | desc |
|---|---|
| hfile.MAX_TAGS_LEN | cell中 存储tags的最大byte 长度 |
| hfile.TAGS_COMPRESSED | boolean value. 是否压缩TAGS |
| *注HFile V3 |
版本逻辑结构对比:
HFile 的Block说明
HFile Trailer Block
Trailer Block 记录HFile的版本信息、各部分的偏移值和寻址值(可以看作是HFile的元数据)。查看Trailer Block 信息:
1 | hbase hfile -f /hbase/data/default/xxx_table/fff89b301b32e363c5f95788fb44bb6c/A/5c9c11f43b9d4b52a53e62d4ea1dc6b4 -m |
内容:
1 | reader=/hbase/data/default/xxx_table/fff89b301b32e363c5f95788fb44bb6c/A/5c9c11f43b9d4b52a53e62d4ea1dc6b4, |
Data Block
Data Blocks是存储KeyValue数据,HBase中所有数据都是以KeyValue结构存储在HBase中,内存和磁盘中的Data Block结构:
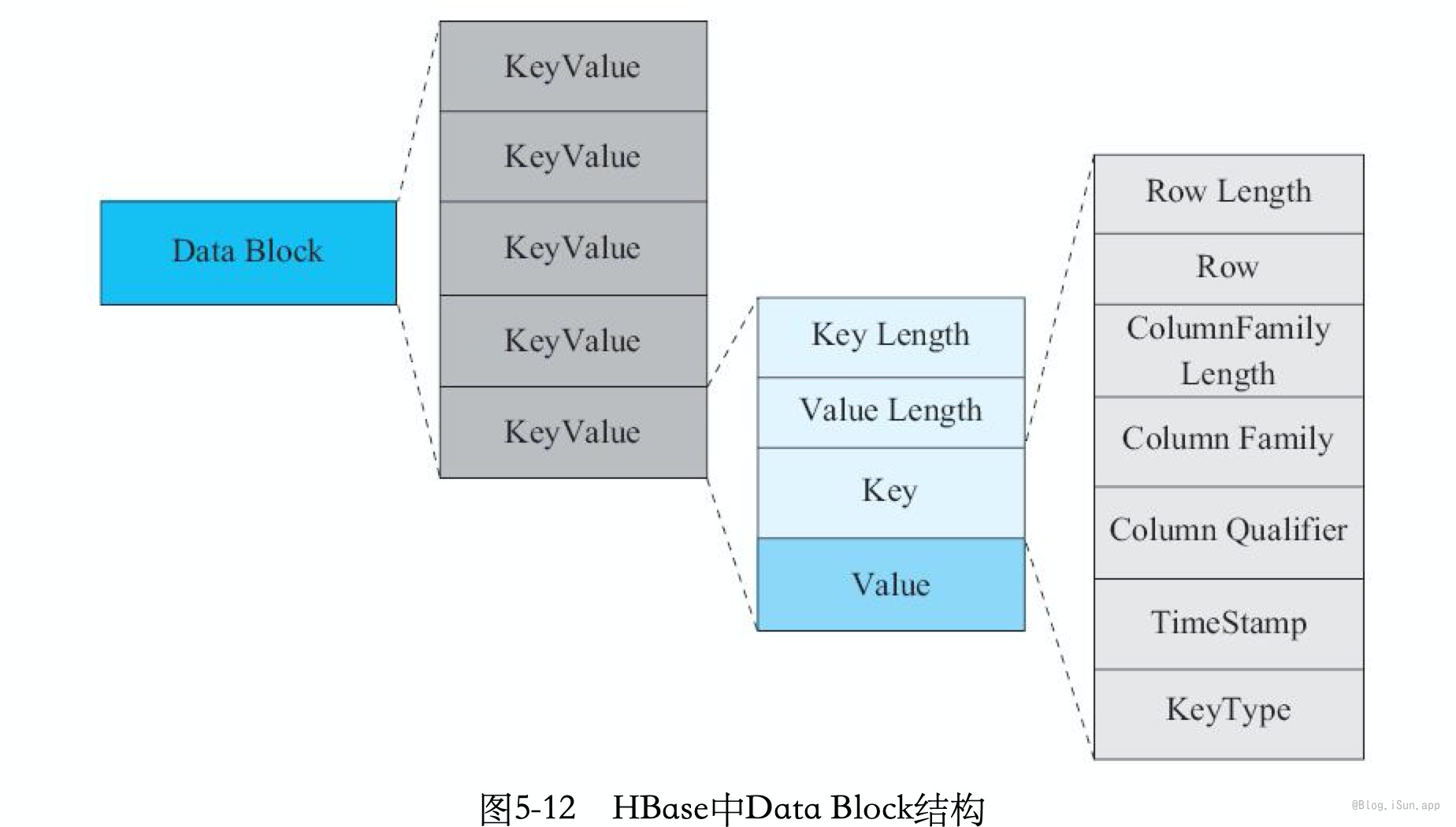
KeyValue由:Key Length, Value Length, Key和Value。其中Key是一个复合结构,由多个部分构成:Rowkey、Column Family、Column Qualifier、TimeStamp以及KeyType。所以,任意的KeyValue都包含Rowkey、Column Family、Column Qualifier(TimeStamp(long类型 8byte/KeyType(枚举)是定长的,占用空间较小),因此这种存储方式比直接存储Value占用更多的存储空间。也是HBase表结构设计时经常强调Rowkey、Column Family以及Column Qualifier尽可能设置短的根本原因。
Bloom Block 以及 Bloom Index Block结构
布隆过滤器(Bloom)对HBase的数据读取性能至关重要。(原因:LSM树对写入非常友好,对读取并不十分友好(遍历),使用布隆过滤器(Bloom)可以进行相应优化,可以直接判断HFile是否存在待检索Key,同时使用了多层Bloom数位组)
Bloom Block 在HFile V2中Bloom Filer位数组进行了拆分,可以拆分为多个位数组,每个位数组就对应一个Bloom Block。
Bloom Index Block 在存在多个Bloom Filter位数组时候,为了提高效率使用Bloom Index Block来定位不同的位数组。Bloom Index Block内存和逻辑结构:

Bloom Index Block的Bloom Index Entry的BlockOffset是一个指向Bloom Block在HFile中的偏移量。 在实现上由CompoundBloomFilterBase.java进行数位组的查找和定位:
使用一个二维数组表示多个BloomFilter的多个数位组,以及关联的Block的position:


1 | public static int binarySearch(byte[][] arr, byte[] key, int offset, int length) { |
所以: Get请求根据Bloom Filter进行过滤查找,可分为三步: Key 在BloomIndexBlock 所有BlckKey二分查找到,定位到Bloom Index Entity > 使用Bloom Index Entity加载对应的位数组 ---> 对key进行Hash Mapping ,对数位组进行查找(! All 1 == 存在)
HFile 基本命令
1 | $ hbase hfile |
参考
- 胡争,范欣欣. HBase原理与实践 (Chinese Edition) (p. 150). Kindle 版本.
- Title: HBase HFile 基本概念
- Author: Ordiy
- Created at : 2021-05-01 18:18:45
- Updated at : 2026-03-23 15:48:10
- Link: https://ordiy.github.io/posts/2021-05-01-hbase-hfile/
- License: This work is licensed under CC BY-NC-SA 4.0.