HBase2 YCSB benchmark test
测试环境说明
机器/网络 环境:
| - | 配置说明 |
|---|---|
| 物理机器配置信息 | CPU32C , 64G Memory , 3T 磁盘 (10个挂载) ,万兆网卡 |
| 虚拟化 | 无 (物理机器运行) |
| 网络 | 万兆网卡/100G交换机 |
| 机柜/机架情况 | 所有节点在同机架 |
| OS 版本 | Centos 7.5 |
软件版本:
| - | 配置说明 |
|---|---|
| HBase | 2.1.6-CDH3.1.5 |
| HDFS | 3.1.1-CDH3.1.5 |
| ambari | 2.7.4-CDH3.1.5 |
| JDK | 1.8_u181 |
| YCSB | 0.18.0-SNAPHOT |
测试方案
测试说明:
| - | 说明 |
|---|---|
| 目的 | 测试HBase在生产环境的下的基准性能 |
| 数据量 | 4T(按照生产环境 预估),1000+ Region .YCSB 一次写入1kb,4T数据约需要43亿行(4 * 1024 * 1024 * 1024 ) |
场景设计
| 场景 | ycsb workload name | desc | 分布 |
|---|---|---|---|
| 读0% / 写100% | workload_g | 单写入场景/SYNC_WAL | Zipfian:随机选择记录,存在热记录 |
| 读20% / 写80% | workload_h | 读少些多场景 | Zipfian:随机选择记录,存在热记录 |
| 读20%/ 写80% | workload_j | 读多写少场景 | Zipfian:随机选择记录,存在热记录 |
| 读100%/写0% | workload_m | 全读取 | Zipfian:随机选择记录,存在热记录 |
| 补充测试场景-读100%/写0% | workload_m | 全读取 | uniform:全随机选择记录,不存在热记录 |
工具准备
YCSB 工具当前的Release版本是1.7,对应的Hbase client 版本是2.0.0,最新master分支的代码使用client是2.3.6,这里选用master分支上的最新代码自行编译和构建。
1 | $ git clone https://github.com/brianfrankcooper/YCSB.git |
进行测试
准备-测试数据
hbase 创建测试表
1 | # 用的机器是HDD的磁盘 |
准备写入数据:
1 | # 这一步耗时很长,我这边用了24H 多写入了 |
执行测试场景A 读0%/写100%
写入数据完成,执行测试场景A:
1 | $ cat << EOF > workloads/workloadm |
测试结果:
1 | #ycsb 测试结果 |
测试机器负载:
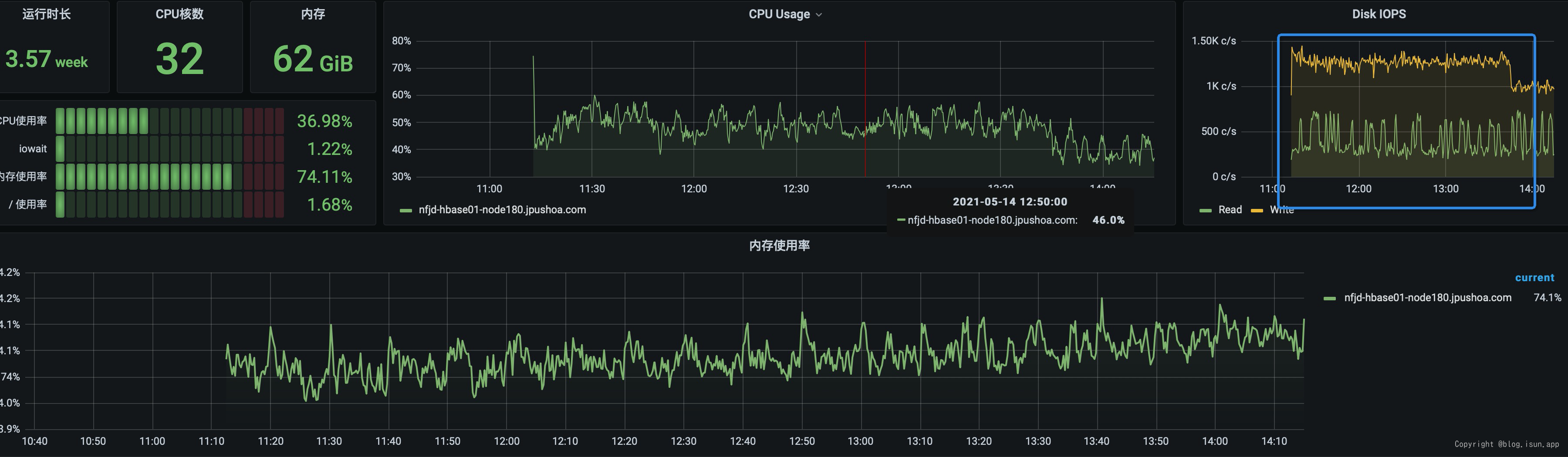
QPS 监控:

执行测试B-读20%写80%
1 | $ cat << EOF > workloads/workloadg |
YCSB 测试结果:
1 | [OVERALL], RunTime(ms), 8444494 |
执行测试C-读80%写20%
1 | $ cat << EOF > workloads/workloadh |
测试结果:
1 | [OVERALL], RunTime(ms), 1622208 |
测试场景D - 读100% / 写0%
1 |
|
测试结果:
1 | [OVERALL], RunTime(ms), 31251027 |
测试场景E-uniform 读100%/写0%
1 | $ cat << EOF > workloads/workloadj_uniform |
测试结果:
1 | [OVERALL], RunTime(ms), 10907660 |
测试数据汇总
测试结果-汇总表:

图表表示(不包含 uniform分布):
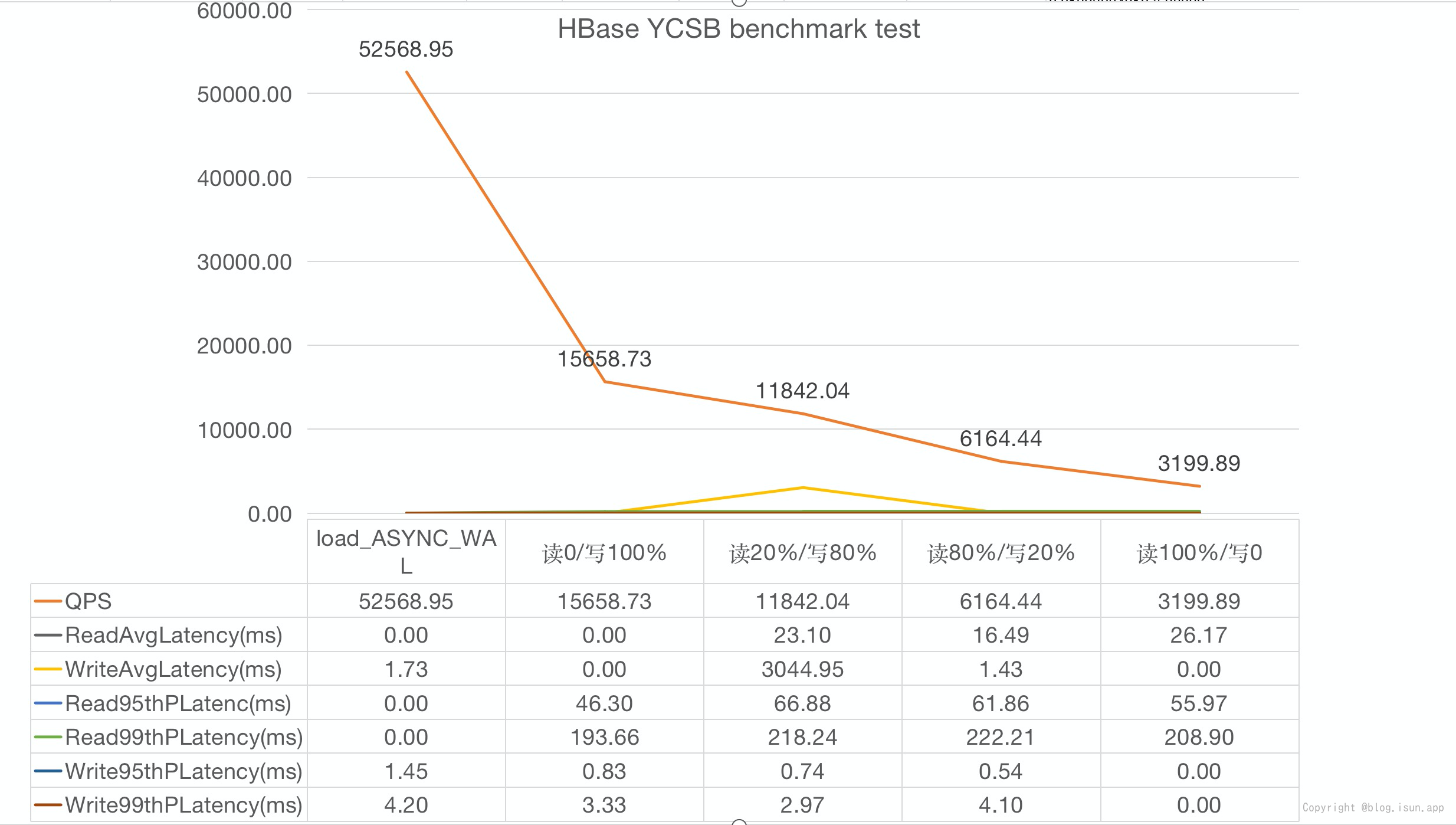
测试总结
- 从上图可以看出 HBase的GET 读操作是主要的性能瓶颈,主要是收到
BlockCache HitRatio和Disk IOPS的影响:
RegionServer Hit Ratio :
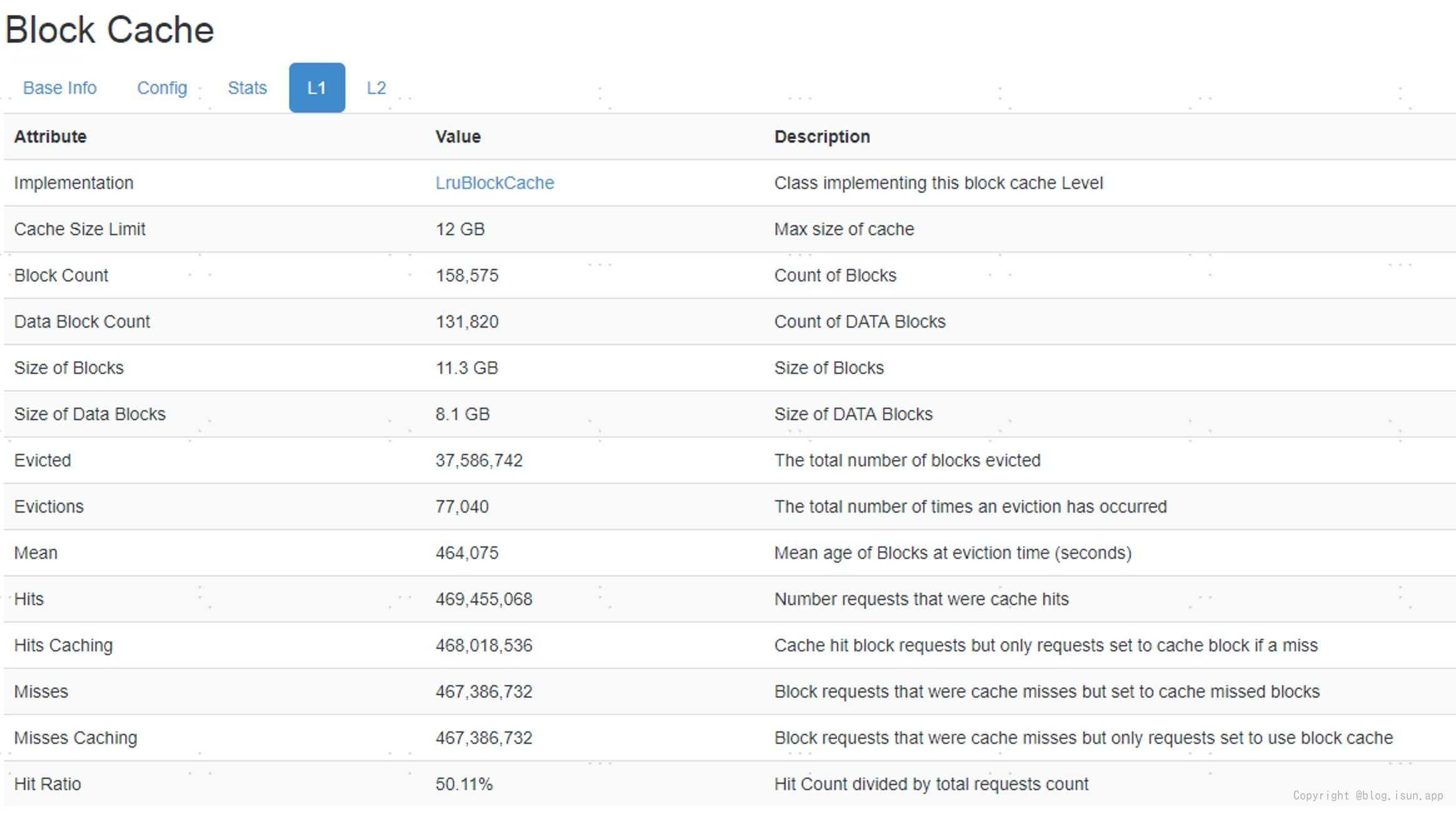 一个机器的最大内存是64G,分配给RegionServer 的BlockCache L1 总量是12G,集群RegionServer L1 Cache总共35G(12G * 3节点), 能够缓存的数据量有限。
测试中 GET RPC 的BlockCache Hit Ratio 一直在50%左右(和生产环境接近),还有50% 的 RPC 请求需要到HDFS存储中访问数据(需要读磁盘),导致latency较大,成为限制QPS提升的瓶颈。
一个机器的最大内存是64G,分配给RegionServer 的BlockCache L1 总量是12G,集群RegionServer L1 Cache总共35G(12G * 3节点), 能够缓存的数据量有限。
测试中 GET RPC 的BlockCache Hit Ratio 一直在50%左右(和生产环境接近),还有50% 的 RPC 请求需要到HDFS存储中访问数据(需要读磁盘),导致latency较大,成为限制QPS提升的瓶颈。
关于Disk IO ,磁盘最大OPS:1K OPS左右,如图:
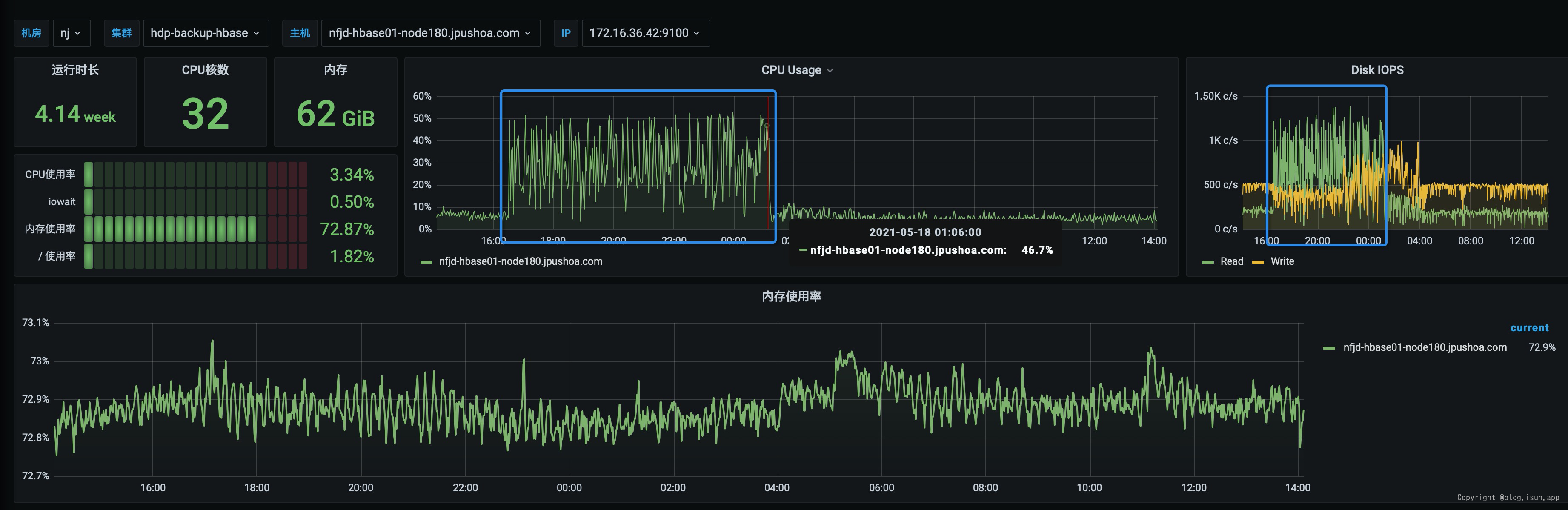 机器最大IOPS: 机器有10个挂载,单个HDD盘的读写
机器最大IOPS: 机器有10个挂载,单个HDD盘的读写 150IOPS左右,所以10挂载 * 150 IOPS = 1.5K OPS,从监控看磁盘OPS基本已经达到上限。
- 相对与zipfian分布的测试,uniform分布下,Hbase 读取性能还要下降2/3 。
这是由于zipfian分布下存在热数据,
YCSB paper中zipfian与uniform对比见: *注意:图片涞源,https://labs.yahoo.com/news/yahoo-cloud-serving-benchmark/
*注意:图片涞源,https://labs.yahoo.com/news/yahoo-cloud-serving-benchmark/
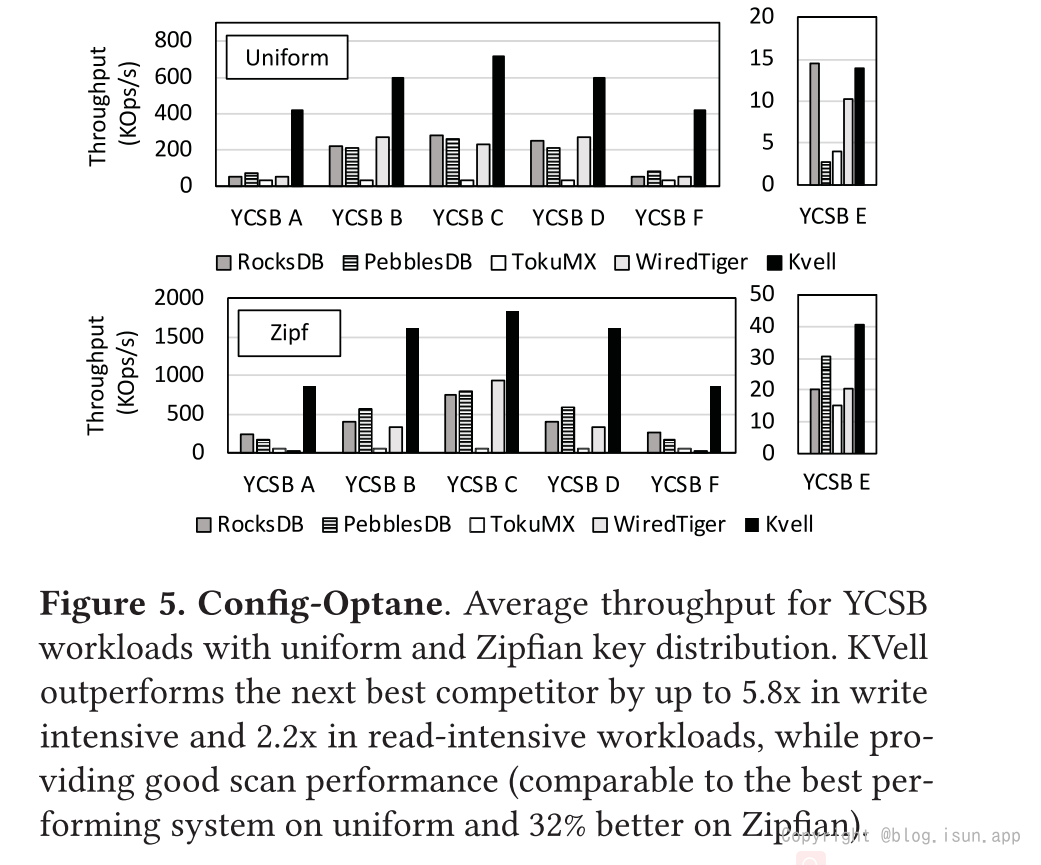 *注意:图片涞源,
*注意:图片涞源,总结
在机器环境不变的情况下,通过提前表的StoreFileSize,可以有效提高表的吞吐量:
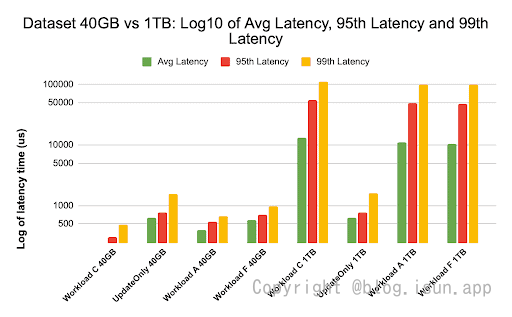 *图片涞源:Surbhi Kochhar,https://blog.cloudera.com/hbase-performance-testing-using-ycsb/
这个图展示了:缓存命中率接近99%(40G数据,cache 命中率100%),并且大多数工作负载数据在缓存中可用,因此延迟要低得多。相比之下,对于1TB数据集,由于必须从HDFS存储访问HFile数据,因此缓存命中率约为85%。
*图片涞源:Surbhi Kochhar,https://blog.cloudera.com/hbase-performance-testing-using-ycsb/
这个图展示了:缓存命中率接近99%(40G数据,cache 命中率100%),并且大多数工作负载数据在缓存中可用,因此延迟要低得多。相比之下,对于1TB数据集,由于必须从HDFS存储访问HFile数据,因此缓存命中率约为85%。
参考文献
YCSB project https://labs.yahoo.com/news/yahoo-cloud-serving-benchmark/
hbase-performance-testing-using-ycsb https://blog.cloudera.com/hbase-performance-testing-using-ycsb/
HBase测试|HBase 2.2.1随机读写性能测试 https://mp.weixin.qq.com/s/V53IHclunWsEMjgxYrbQdQ
Hbase SSD https://blogs.apache.org/hbase/?page=1
- Title: HBase2 YCSB benchmark test
- Author: Ordiy
- Created at : 2021-05-21 11:09:29
- Updated at : 2026-03-23 15:48:10
- Link: https://ordiy.github.io/posts/2021-04-11-hbase-ycsb-benchamark-test-1/
- License: This work is licensed under CC BY-NC-SA 4.0.