HBase写入数据的过程
简介
今天在Tencent面试遇到一个面试问题:请说一下HBase写入数据的过程。 没答到关键点上 -_- 。 做个整理,按照Data从Client写入到HBase Server的整个过程,进行说明。
HBase写数据过程
以HBase-Client 、HBase-Server 、RegionServer三个重要组件为重点,分析HBase写入数据的整个过程。
HBase-Client构建和发送RPC请求 HBase-Client写入数据的Code Demo:
1 | public static void main(String[] args) throws IOException { |
这里重点关注org.apache.hadoop.hbase.client.Put 对象的数据结构:
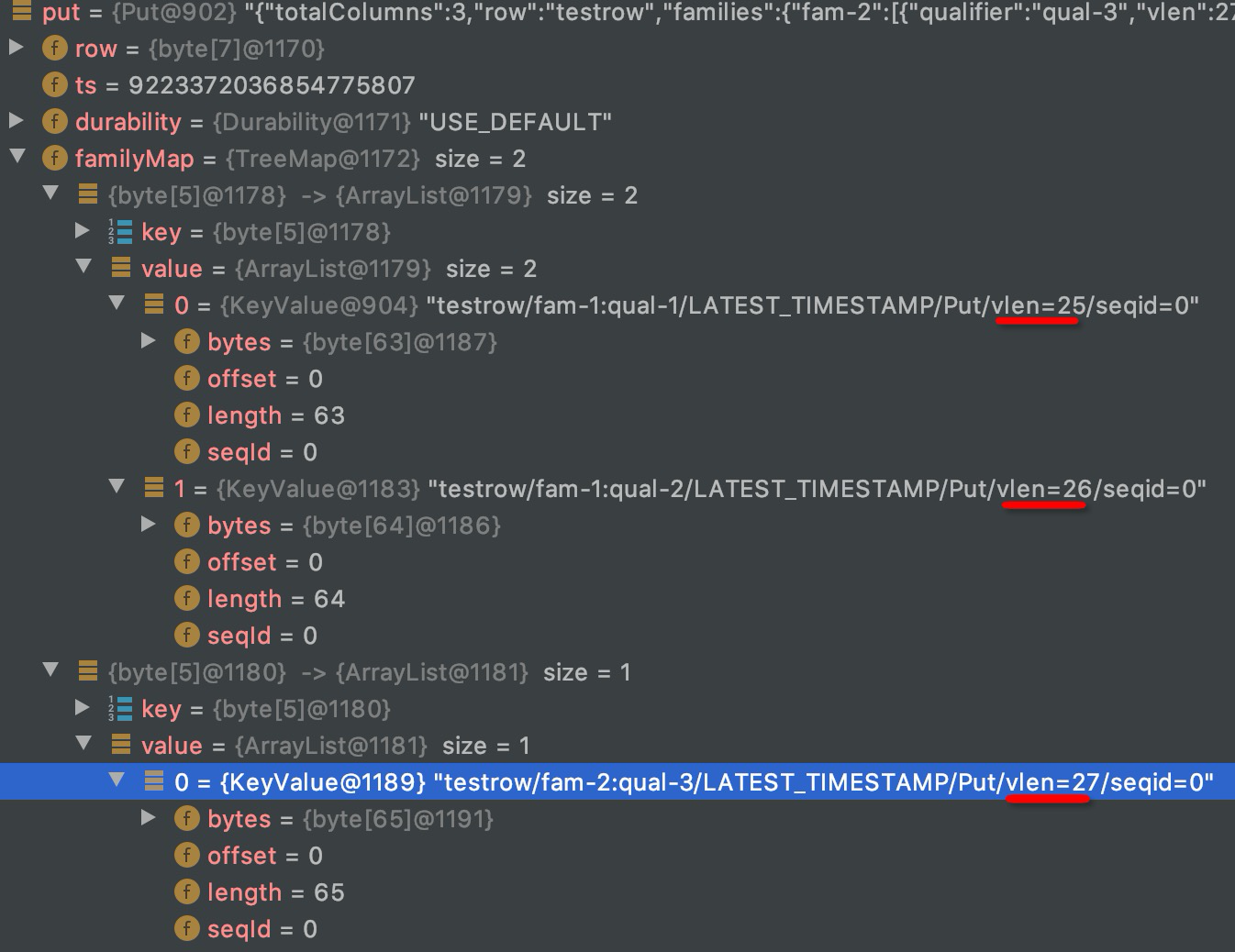
Put对象的row、列簇、列名、value都被转换为了一个KeyValue对象(KeyValue对象内是一个由row、列簇、列名、value等拼接成的byte类型的数组),Put会使用 protobuf序列化框架转换为一个的RPC,发送到HBase-Server。
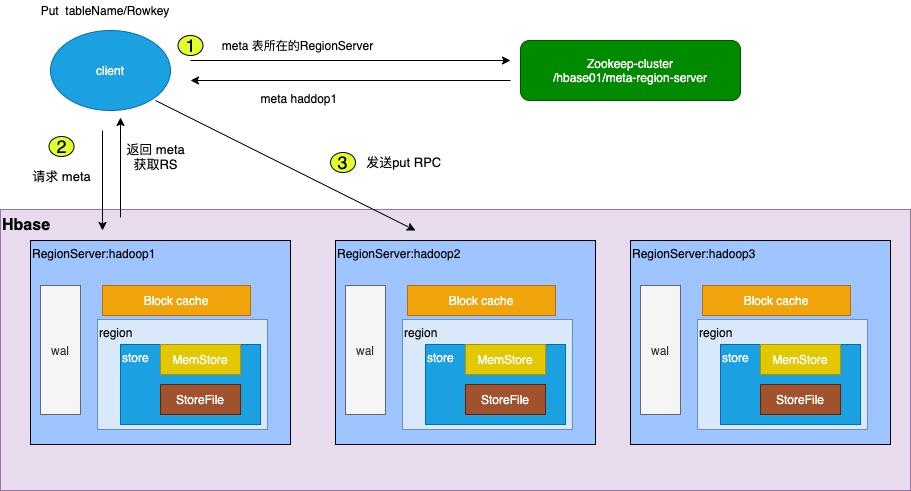
HBase-Server 接收数据的过程 将写入数据过程抽象为以下阶段:ZK获取metadata, 根据metadata连接到RegionServer获取到此次写入数据的目标RegionServer,向目标RegionServer写数据,目标RegionServer执行IO请求。(这里省略了HBase内部的数据存储过程)。

RegionServer执行IO请求 RegionServer主要作用是用来响应用户的IO请求,是HBase的核心模块,有WAL(HLog)、BlokCache以及多个Region组成。 HBase写入数据并非直接写入到HFlie数据文件,而是先写入缓存,再异步刷行落盘。为了防止缓存数据丢失,数据写入缓存之前需要先写入到HLog,这样缓存即使丢失,仍然可以通过HLog日志恢复;另外HBase集群实现集群间的主 复制,通过回放主集群推送过来的HLog日志实现主从复制。
HBase基本知识
补充一些关于HBase数据模型的基本知识,以便于更好的理解这个过程。
HBase 逻辑试图
多维稀疏排序Map BigTable论文中称BigTable为"spares,distributed,persistent,multidimensional sort map"。BigTable本质是一个Map结构数据库,HBase亦然,也是一系列KV构成. HBase的Map的Key是一个复合键,由rowkey,column,family,qualifiter,type以及timestamp组成,value即为cell的值。 例如:

1 | {"com.cnn.www","anthor","cnsi.com","put",153212121} -> "CNN" |
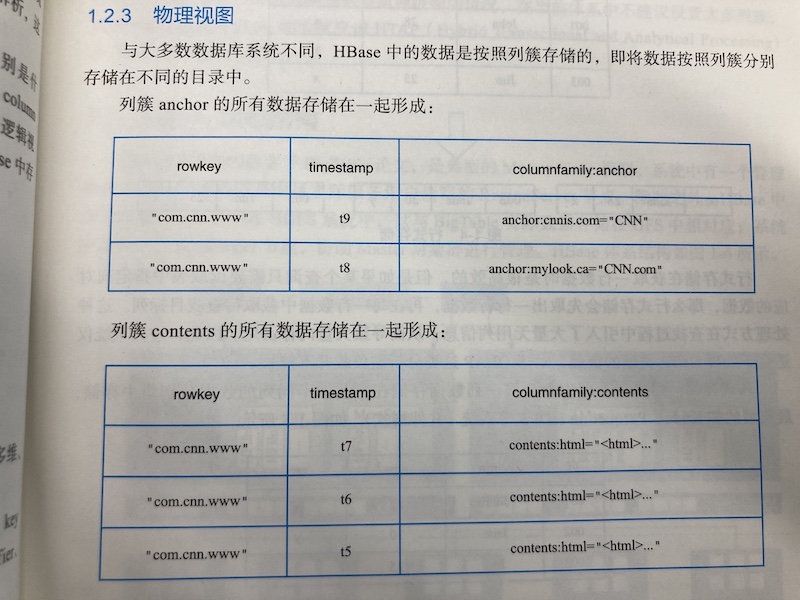
HBase 物理视图 HBase中数据是按照列簇存储的,即将数据按照列簇分别存储在不通目录中。
HBase 体系结构

参考文献
- HBase原理与实践.机械工业出版社
- apache hbase book
- Understanding HBase and BigTable
- Title: HBase写入数据的过程
- Author: Ordiy
- Created at : 2021-02-05 00:00:00
- Updated at : 2026-03-23 15:48:10
- Link: https://ordiy.github.io/posts/2021-02-05-hbase-writer-process/
- License: This work is licensed under CC BY-NC-SA 4.0.